“参数”将混合专家推向极限:只需更新0.32%的参数就能完成模型微调
今天,很高兴为大家分享来自机器之心Pro的将混合专家推向极限:只需更新0.32%的参数就能完成模型微调,如果您对将混合专家推向极限:只需更新0.32%的参数就能完成模型微调感兴趣,请往下看。
微调无需更新全部模型参数,这种方法只需更新不到 1% 的参数。
众所周知,大模型的训练成本很高,但其实对预训练后的模型进行微调也需要一定的成本,还好我们已经有了 (IA)³ 或 LORA 等一些参数高效型微调(PEFT)方法。
近日,AI 创业公司 Cohere 更进一步,将混合专家方法与 PEFT 组合,实现了极其参数高效的微调 —— 即使是在未曾见过的任务上,这种新方法只需更新不到 1% 的参数,就能实现与完全微调方法相当的性能。
Cohere 公司在攻克这些挑战上迈出了重要一步,提出了一个新框架 —— 可在大幅受限的计算环境中利用 MoE 的优势。

论文链接:https://arxiv.org/abs/2309.05444
代码链接:https://github.com/for-ai/parameter-efficient-moe
传统的训练范式是将模型的权重应用于每个输入。有理由相信这种方法效率不高,因为单个输入可能无法让模型发挥全部力量。
相比之下,混合专家(MoE/Mixture of Experts)则是基于多个子模块组件(即所谓的专家),这些组件可以专门处理不同类型的输入。这种对于条件计算的强调对效率具有重要的影响,比如会有恒定的推理成本。这使得 MoE 成了大规模 Transformer 时代一个重要的研究领域并得到了广泛的采用;而在这些应用中,规模的扩张也会造成部署成本和延迟上升。
尽管截至目前的大部分研究关注的是将 MoE 用作一种预训练策略,但 MoE 的内在动机并不仅局限于预训练。事实上,MoE 具有一些非常适合指令微调的特性;在指令微调设置中,数据会被刻意地构建,以代表多样化的任务,这通常也被称为多任务微调。
基于这一观察,AI 创业公司 Cohere 提出了一个问题:能否使用 MoE 来进行指令微调?MoE 范式的一大主要缺点是会引入大量参数。尽管是基于条件执行计算,但完全微调 MoE 架构需要更新所有参数,这需要非常大量的计算。对于大多数实践者来说,考虑到现代 LLM 的规模,这样的计算成本是无力支撑的。
于是,Cohere 公司关注的是更为现实的实践场景,即将 MoE 用于参数高效型微调(PEFT)方法,如 (IA)³ 或 LORA,它们微调的参数数量会少很多。这是一个重大挑战,不仅因为目标是仅更新所有参数的一小部分,而且因为还要在更受限的环境中解决 MoE 固有的优化挑战。
他们引入了 Mixture of Vectors(MoV)和 Mixture of LORA(MoLORA),一种参数高效型混合专家适应方法。不同于标准的 MoE,这种新框架很轻量,可用于对参数有限制的场景。
值得注意的是,在未曾见过的任务上,这种新方法只需更新不到 1% 的参数,就能实现与完全微调方法相当的性能。其表现也能轻松胜过 (IA)³ 或 LORA 等基础的参数高效型技术。
该团队基于 55 个数据集,在 12 个不同任务上,用 770M 到 11B 的不同大小 T5 模型进行了实验,得到了相当一致的结果。

本文的主要贡献包括:
1. 提出了极其参数高效的 MoE。该架构利用了模块化和轻量级的专家,可在更加现实的设置中使用 MoE。使用这个新提出的 MoE 来训练一个密集模型时,仅需更新其不到 1% 的参数。
2. 使用新提出的方法执行指令微调时,在未曾见过的任务上能取得持续优于传统参数高效方法的性能,同时还能为不同大小的模型维持较高的参数效率。相较于 3B 和 11B 模型大小的标准 (IA)³,混合 (IA)³ 向量(MoV)分别实现了 14.57% 和 8.39% 的提升。这种优越性在各种大小的模型、各种类型的专家和可训练参数负载上都有体现。
3. 研究表明新提出的方法能取得与大规模完全微调方法相当的性能表现,同时只需更新一小部分模型参数。研究者在 8 个未曾见过的任务上进行了实验,结果表明 MoV 仅会分别更新 3B 和 11B 模型中 0.32% 和 0.86% 的参数,却能以显著更低的计算成本实现与完全微调方法相当的表现。
4. 他们也进行了一系列广泛的消融研究,系统性地评估了各种 MoE 架构和 PEFT 策略的效能,涉及多种模型大小、不同的适应器类型、专家的数量、路由机制和优化超参数的重要性,尤其是考虑到 MoE 的敏感性。
方法
指令微调可以形式化地表述为:存在一个任务集合 T,将其分为训练任务集 T_train 和留存评估集 T_eval。
首先在 T_train 上对基础预训练模型进行微调,然后使用零样本方式在 T_eval 中的每个任务上评估微调后的模型。标准的微调方法是微调所有模型参数,这样会有很高的计算和内存成本。新提出的方法却有很高的参数效率,其使用了参数高效型混合专家,下面详细描述一下该框架。
(IA)³ 和 LORA 参数高效型微调方法
参数高效型微调(PEFT)方法只会更新少量参数的权重。为了展示新方法适用于不同的 PEFT 技术,研究者实验了 (IA)³ 和 LORA。这些方法会向已有的预训练模型模型添加少量参数。这里就不对 (IA)³ 和 LORA 做更详细的介绍了,感兴趣的读者可参阅原论文以及机器之心的报道《调教 LLaMA 类模型没那么难,LoRA 将模型微调缩减到几小时》。
极其参数高效的混合专家
新提出的极其参数高效的 MoE 框架使用了轻量级的「适应器」作为预训练密集模型之上的专家。
具体来说,MoE 是一系列神经网络架构,可以通过基于门控机制(路由器)激活的多个专家来进行条件计算。MoE 层由一个路由器网络 R 和一个专家集合 E 构成,其中 E 包含 n 个专家,每个专家 E_i 都是一个已参数化的函数。至于路由器网络 R 的设计,该团队参照了论文《Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity》,通常由一个密集层后带一个 softmax 函数构成;其中这个密集层有可训练的权重 W_g,softmax 函数则是以中间 token 表征 x 为输入并基于门控分数 s_1, ..., s_n 将每个专家的输出组合到一起:

对于 Transformer 模型,其中的密集型前向层被 MoE 层取代,该层中每个专家 E_i 都对应于一个独立的密集型前向网络。随着每个专家的规模和专家数量的增加,模型的参数总数会成倍增大。但是,在新提出的参数高效型 MoE 架构中,每一个专家都被一个轻量级 PEFT 适应器(比如 (IA)³ 向量或 LORA 适应器)替代。
在微调过程中,密集层的预训练权重保持固定,而专家层和路由器层则从头开始训练。不同于标准 MoE,这种新提出的轻量级专家可以在微调时间学习适应预训练 Transformer 层。这样一来,新的 MoE 框架只需要少量参数更新,而不是整体对大模型进行更新。
除了参数效率之外,研究者选择的 PEFT 适应器可通过 soft merging 实现路由计算。具体来说,由于 (IA)³ 向量和 LORA 适应器都是线性函数,所以他们首先会计算专家的加权平均,然后使用组合后的专家 E_mix 应用一个 PEFT 变换:

对于把 (IA)³ 向量或 LORA 适应器分别用作专家的方法,研究者将它们分别命名为 Mixture of Vectors (MoV) 和 Mixture of LORA (MoLORA),这两种方法都能持续稳定地优于对应的 PEFT 方法。下图 2 展示了 MoV 层的架构以及相应的伪代码。

通过 MoV 和 MoLORA 只更新少部分参数有一些实际的好处 —— 不仅有益于训练,也有助于推理;对于后者的优势是 MoE 架构所独有的。下面简要描述一些这些好处:
训练效率
这种极其参数高效的 MoE 形式可以显著减少内存消耗。通过在训练期间冻结大多数参数,不仅能减少计算模型参数的梯度的计算开销,而且还可降低存储模型的优化器状态的内存需求。根据优化器的选择,后者可能非常重要,举个例子,AdamW 等 Adam 优化器变体为了存储优化器状态,每个参数需要两倍的内存(根据一阶矩和二阶矩的估计),而 Adafactor 则能通过分解二阶参数矩的估计来将这种开销减半。
推理效率
MoV 和 MoLORA 方法的固有结构模块化特性能为推理带来显著的内存效益。对于传统的 MoE 模型,很多完全用于前向的块的副本(甚至基于特定架构的模型的完整副本)需要在推理时间被存储在内存中,这种做法的成本很高。
使用这种方法,不管确切的类型如何,都只需要将模型主干的一个副本保存在内存中,外加上轻量级参数高效型专家。这能在推理时间显著降低对内存的需求。
实验
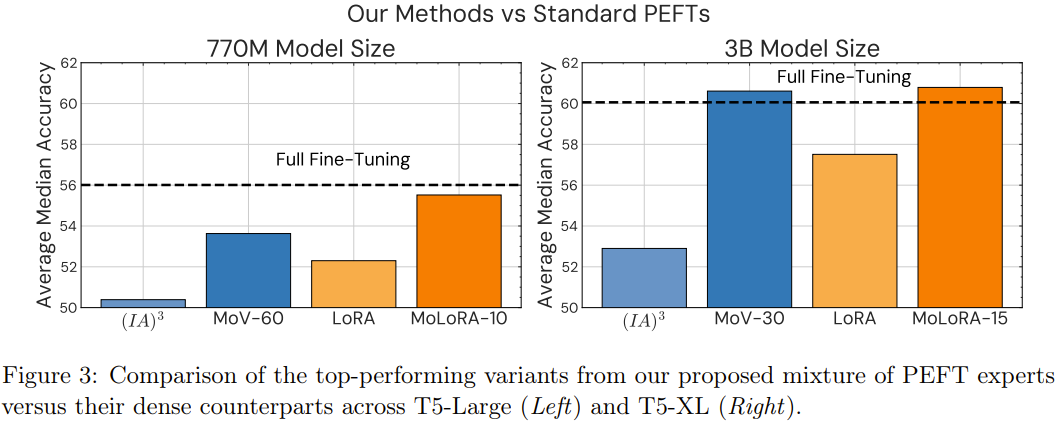
参数高效型 MoE 与 PEFT 方法:新的 MoE 方法与单专家型 PEFT 方法相比如何?下表 1 比较了 PEFT 方法((IA)³ 和 LORA)与新提出的参数高效型 MoE 方法(MoV 和 MoLORA)的零样本性能,其中基础模型是 T5-3B。

可以观察到,相比于标准的 (IA)³ 向量和 LORA 适应器,MoE 变体(MoV 和 MoLORA)的性能有显著优势。
比如,使用 30 个专家的 MoV 的表现优于密集型 (IA)³ 方法 14.57%,使用 15 个专家的 MoLORA 则在平均中值分数上提升了 5.70%。
在同样的参数负载下,MoV 的表现胜过 MoLORA。研究者也比较了新提出的两种方法:使用 3B 参数的基础模型时,MoV 在性能与参数成本的权衡方面表现更好。
参数高效型 MoE 与完全微调方法的对比。如表 1 所示,与完全微调的 T0-3B 相比,使用 10 个专家的 MoV 和 MoLORA 的性能相当。这是一个非常亮眼的结果,因为 MoV-10 仅更新了全体模型参数中的 0.32%。而如果将 MoV 的专家数增至 15,将 MoLORA 的专家数增至 30,新方法的效果甚至能小幅胜过完全微调方法。
此外,研究者还通过实验探索了参数高效型 MoE 随基础模型大小增长的性能变化情况、专家数量对下游任务性能的影响、最优的路由策略等方面,详见原论文。
好了,关于将混合专家推向极限:只需更新0.32%的参数就能完成模型微调就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “西湖”西湖大学成立5周年,施一公:做创新的守护者是使命也是未来
- “儿子”妈妈将50余万“读书钱”存儿子名下,19岁儿子取出转给女友,妈妈无奈起诉追回
- “力学”王博已任大连理工大学副校长
- “说了”云朵的话语,心灵的方剂 ——读周实《有些话语好像云朵》
- “超新星”云南天文台发现Ia型超新星前身星候选体
- “科幻”和成都和教育,一起遇见未来!两份重要“科幻教育”名单公布
- “红星”梁静茹南京演唱会再现“柱子票” 主办方:临时布置追光灯,正与观众沟通
- “导盲犬”视障女子自曝带导盲犬进公园遭保安阻拦 公园方:天色较晚不知其实情,沟通后已放行
- “小行星”首次!我国计划实施近地小行星防御任务
- “肿瘤”科学家揭示肿瘤免疫逃逸新机制,鉴定三个癌症生存相关因子,为肿瘤免疫治疗注入新动力
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等
- “融资”国内AI大模型赛道火热,大厂积极跟投布局
- “模型”在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了
- “图像”OpenAI终于Open一回:DALL-E 3论文公布、上线ChatGPT,作者一半是华人









