“表征”OpenAI新模型用的嵌入技术被网友扒出来了
今天,很高兴为大家分享来自机器之心Pro的OpenAI新模型用的嵌入技术被网友扒出来了,如果您对OpenAI新模型用的嵌入技术被网友扒出来了感兴趣,请往下看。
学起来吧。

前几天,OpenAI 来了一波重磅更新,一口气宣布了 5 个新模型,其中就包括两个新的文本嵌入模型。
我们知道,嵌入是表示自然语言或代码等内容中概念的数字序列。嵌入使得机器学习模型和其他算法更容易理解内容之间的关联,也更容易执行聚类或检索等任务。
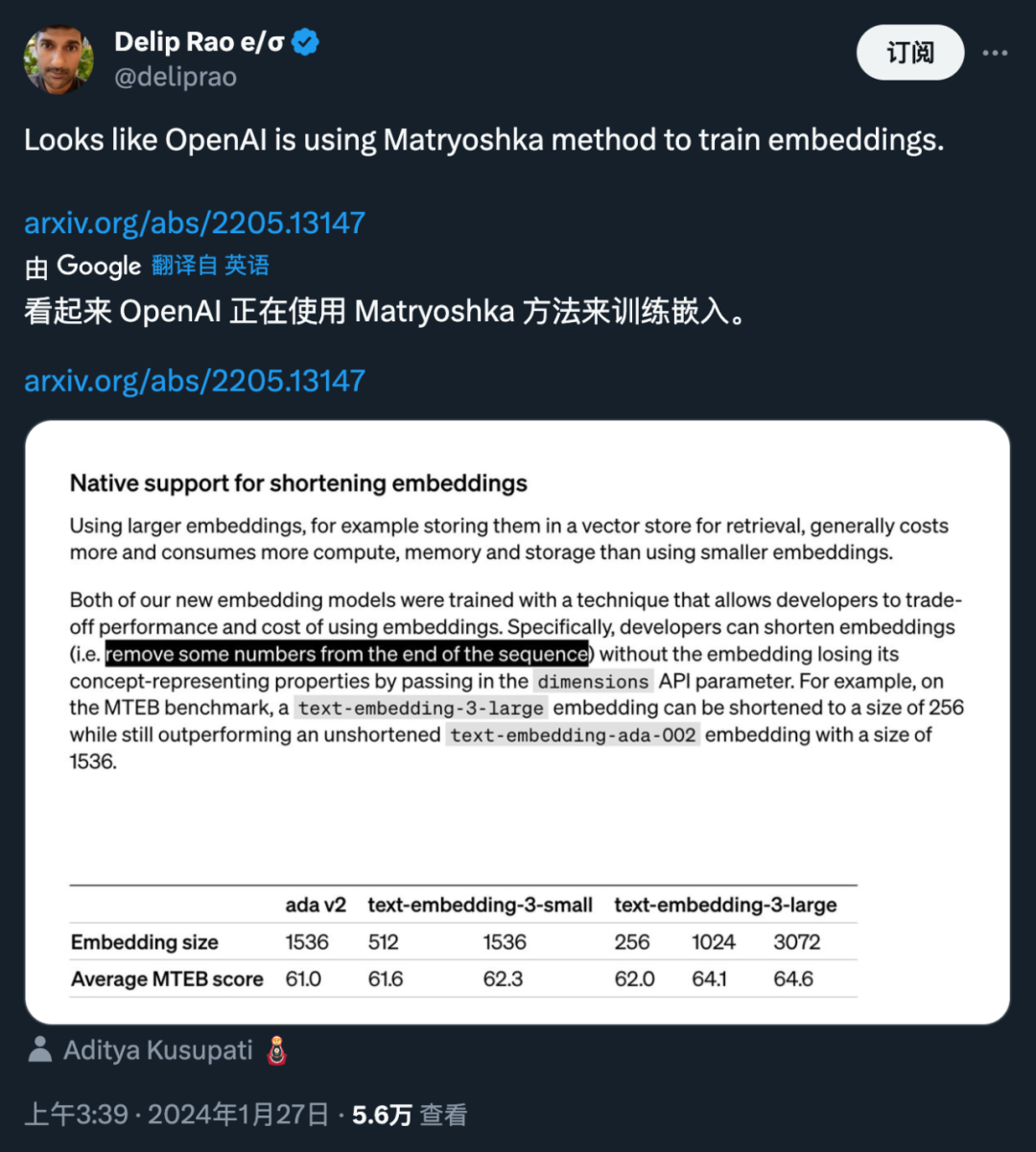
使用更大的嵌入(比如将它们存储在向量存储器中以供检索)通常要比更小的嵌入消耗更高的成本、以及更多的算力、内存和存储。而 OpenAI 此次推出的两个文本嵌入模型分别是更小且高效的 text-embedding-3-small 模型和更大且更强大的 text-embedding-3-large 模型。
这两个新嵌入模型都使用一种技术进行训练,允许开发人员权衡使用嵌入的性能和成本。具体来说,开发者通过在 dimensions API 参数中传递嵌入而不丢失其概念表征属性,从而缩短嵌入(即从序列末尾删除一些数字)。例如在 MTEB 基准上,text-embedding-3-large 可以缩短为 256 的大小, 同时性能仍然优于未缩短的 text-embedding-ada-002 嵌入(大小为 1536)。

这一技术应用非常灵活:比如当使用仅支持最高 1024 维嵌入的向量数据存储时,开发者现在仍然可以使用最好的嵌入模型 text-embedding-3-large 并指定 dimensions API 参数的值为 1024,使得嵌入维数从 3072 开始缩短,牺牲一些准确度以换取更小的向量大小。
OpenAI 所使用的「缩短嵌入」方法,随后引起了研究者们的广泛注意。
人们发现,这种方法和 2022 年 5 月的一篇论文所提出的「Matryoshka Representation Learning」方法是相同的。
而 MRL 的一作 Aditya Kusupati 也现身说法:「OpenAI 在 v3 嵌入 API 中默认使用 MRL 用于检索和 RAG!其他模型和服务应该很快就会迎头赶上。」

那么 MRL 到底是什么?效果如何?都在下面这篇 2022 年的论文里。
MRL 论文介绍

论文标题:Matryoshka Representation Learning
论文链接:https://arxiv.org/pdf/2205.13147.pdf
研究者提出的问题是:能否设计一种灵活的表征方法,以适应计算资源不同的多个下游任务?
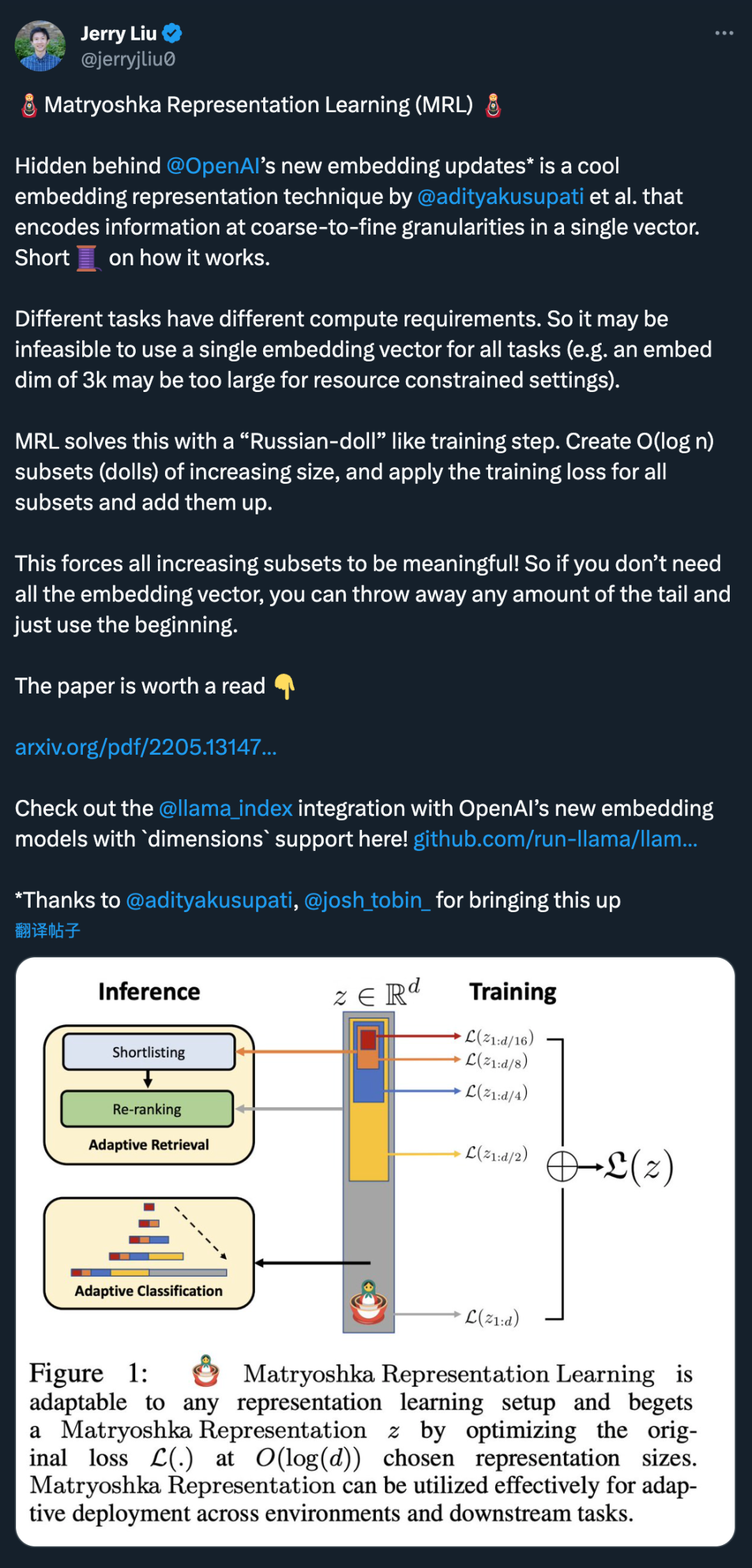
MRL 通过以嵌套方式对 O (log (d)) 低维向量进行显式优化在同一个高维向量中学习不同容量的表征,因此被称为 Matryoshka「俄罗斯套娃」。MRL 可适用于任何现有的表征 pipeline,并可轻松扩展到计算机视觉和自然语言处理中的许多标准任务。
图 1 展示了 MRL 的核心理念以及所学习 Matryoshka 表征的自适应部署设置:

Matryoshka 表征的第一个 m-dimensions(m∈[d])是一个信息丰富的低维向量,不需要额外的训练成本,其精确度不亚于独立训练的 m 维表征法。Matryoshka 表征的信息量随着维度的增加而增加,形成了一种从粗到细的表征法,而且无需大量的训练或额外的部署开销。MRL 为表征向量提供了所需的灵活性和多保真度,可确保在准确性与计算量之间实现近乎最佳的权衡。凭借这些优势,MRL 可根据精度和计算约束条件进行自适应部署。
在这项工作中,研究者将重点放在了现实世界 ML 系统的两个关键构件上:大规模分类和检索。
在分类方面,研究者使用了自适应级联,并使用由 MRL 训练的模型产生的可变大小表征,从而大大降低了达到特定准确率所需的嵌入式平均维数。例如,在 ImageNet-1K 上,MRL + 自适应分类的结果是,在精度与基线相同的情况下,表征大小最多可缩小 14 倍。

同样地,研究者在自适应检索系统中也使用了 MRL。在给定一个查询的情况下,使用查询嵌入的前几个 dimensions 来筛选检索候选对象,然后连续使用更多的 dimensions 对检索集进行重新排序。与使用标准嵌入向量的单次检索系统相比,这种方法的简单实现可实现 128 倍的理论速度(以 FLOPS 计)和 14 倍的墙上时钟时间速度;需要注意的是,MRL 的检索精度与单次检索的精度相当(第 4.3.1 节)。

最后,由于 MRL 明确地学习了从粗到细的表征向量,因此直观地说,它应该在不同 dimensions 之间共享更多的语义信息(图 5)。这反映在长尾持续学习设置中,准确率最多可提高 2%,同时与原始嵌入一样稳健。此外,由于 MRL 具有粗粒度到细粒度的特性,它还可以用作分析实例分类难易程度和信息瓶颈的方法。

更多研究细节,可参考论文原文。
好了,关于OpenAI新模型用的嵌入技术被网友扒出来了就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “表征”OpenAI新模型用的嵌入技术被网友扒出来了
- “哮喘”《祝你平安》孙悦披露为何隐退8年:为治儿子哮喘
- “手机”西湖大学校长施一公团队最新研究:手机辐射恐影响发育!
- “厦门市”厦门市公示赛马制揭榜挂帅项目拟立项项目
- “鹈鹕”卷羽鹈鹕东亚种群数量突破150只
- “英特尔”英特尔财报:2023财年英特尔整体收入为542亿美元 同比下降14%
- “体彩”体彩开展推广活动
- “小鹏”小鹏汽车新任生产制造负责人张利来自长城 是总经理王凤英的丈夫?
- “春运”加大警力投入、快速办临时乘车证明……成都路地联动保春运,让回家的路有温度
- “田鸡”被誉为“大自然的舞者”!国家二级保护动物棕背田鸡现身攀枝花,系当地首次发现
- “人工智能”未来五年AI如何改变各学科?从LLM到AI蛋白设计、医疗保健......
- “模型”OpenAI发布多项更新 再度“加量减价”
- “模型”大模型“杀手级”应用还有多远?|《2024金融业生成式AI应用报告》发布暨研讨会内容回顾
- “中国”B站获全球最大规模手办模型展Wonder Festival主办权
- “模型”360集团荣膺“2023年度AI大模型先锋企业”大奖 引领人工智能大模型产业创新发展
- “模型”一张照片,为深度学习巨头们定制人像图片
- “模型”大模型自我奖励:Meta让Llama2自己给自己微调,性能超越了GPT-4
- “机器人”机器人领域首个开源视觉-语言操作大模型,RoboFlamingo框架激发开源VLMs更大潜能
- “论文”ICLR 2024接收率31%,清华LCM论文作者:讲个笑话,被拒了
- “模型”最接近GPT-4的国产大模型诞生了