“句法”架构瓶颈原则:用注意力probe估计神经网络组件提供多少句法信息
今天,很高兴为大家分享来自机器之心Pro的架构瓶颈原则:用注意力probe估计神经网络组件提供多少句法信息,如果您对架构瓶颈原则:用注意力probe估计神经网络组件提供多少句法信息感兴趣,请往下看。
机器之心报道
编辑:陈萍、杜伟
本文中,剑桥和 ETH Zurich 的研究者从一个新的角度探讨了 probing,不关心模型编码了多少信息,而是关心它的组件可以提取多少信息。然后使用 V-information 来量化这个数量。通过评估流行的 transformer 语言模型注意力机制,该研究发现关于句子的语法树信息大部分都可以由模型提取。然而,对于随机初始化的 transformer 模型而言,情况并非如此。因此,该研究得出结论,对 transformer 的训练会导致注意力头具有解码语法树的潜力。
预训练语言模型在各种自然语言处理任务上的惊人表现,引起了人们对其分析的兴趣。Probing 是进行此类分析所采用的最普遍的方法之一。在典型的 probing 研究中,probing 是一个插在中间层的浅层神经网络,通常是一个分类器层。其有助于探查不同层捕获的信息。使用辅助任务对 probing 进行训练和验证,以发现是否捕获了此类辅助信息。
一般来讲,研究者首先冻结模型的权重,然后在模型的上下文表示的基础上训练probe,从而预测输入句子的属性,例如句法解析(其对句子结构进行分析,理清句子中词汇之间的连接规则)。不幸的是,关于如何设计此类 probe 的最佳实践仍然存在争议。
一方面,有研究者倾向于使用简单的 probe,这样就可以将 probe 与 NLP 任务区分开来;另一方面,一些人认为需要复杂的 probe 才能从表示中提取相关信息。此外,还有一些人考虑折中的方法,主张将复杂性 - 准确性帕累托曲线上的 probe 考虑在内。
本文中,来自剑桥大学、苏黎世联邦理工学院的研究者提出架构瓶颈原则 (ABP,architectural bottleneck principle) 作为构建有用 probe 的指南,并试图测量神经网络中的一个组件可以从馈送到它的表示中提取多少信息。为了估计给定组件可以提取多少信息,该研究发现 probe 应该与组件完全相同。根据这一原理,该研究通过注意力 probe 来估计有多少句法信息可用于 transformer。

论文地址:https://arxiv.org/pdf/2211.06420.pdf
举例来说,该研究假设 transformer 的注意力头是其使用句法信息的瓶颈,因为这是 transformer 中唯一可以同时访问多个 token 的组件。根据 ABP,该研究提出注意力 probe,就像注意力头一样。该 probe 回答了这样一个问题:transformer 在计算其注意力权重时可以使用多少句法信息?
结果表明,大多数(尽管不是全部)句法信息都可以通过这种简单的注意力头架构提取:英语句子平均包含 31.2 bit 的句法树结构信息,而注意力 probe 可以提取 28.0 bits 信息。更进一步,在 BERT、ALBERT 和 RoBERTa 语言模型上,一个句子的语法树大部分是可以被 probe 提取的,这表明这些模型在组成上下文表示时可以访问句法信息。然而,这些模型是否真的使用了这些信息,仍然是一个悬而未决的问题。
注意力 Probe
目前,有许多方法用来设计有效的 probe,分类原则大致包括:线性原则、最大信息原则、易提取原则,此外还包括本文提出的 ABP 原则。
可以说 ABP 将前三个原则联系起来。最重要的是,ABP 泛化了线性原则、最大信息原则,此外,ABP 还通过限制 probe 的容量来隐式控信息制提取的难易程度。
该研究重点关注 transformer 注意力机制。此前研究人员曾断言,在计算注意力权重时,transformer 会使用句法信息。此外,注意力头是 transformer 中唯一可以同时访问多个单词的组件。因此,在注意力头的背景下探索 ABP 是一个自然的起点。具体而言,根据 ABP,我们可以研究 transformer 的注意力头可以从输入表示中提取多少信息。
实验结果
对于数据,研究者使用了通用依赖(UD)树库。他们分析了四种不同类型的语言,包括巴斯克语、英语、泰米尔语和土耳其语。此外,研究者将分析重点放在未标记的依赖树上,并注意到 UD 使用特定的句法形式,这可能会对结果造成影响。
对于模型,研究者探讨了以上四种语言的多语言 BERT 以及仅支持英语的 RoBERTa 和 ALBERT。根据 ABP,他们保持 probe 的隐藏层大小与 probed 架构中的相同。最后,他们还将一个具有与 BERT 相同架构的未训练 transformer 模型作为基线。
下图 1 展示了主要结果。首先,研究者的 probe 估计大多数句法信息可以在中间层提取。其次,大量句法信息在馈入注意力头的表示中进行编码。虽然他们估计使用英语、泰米尔语和巴斯克语句子编码的信息接近 31 bits,但使用土耳其句子编码的信息约为 15 bits。研究者怀疑这是因为土耳其语在语料库中的句子最短。
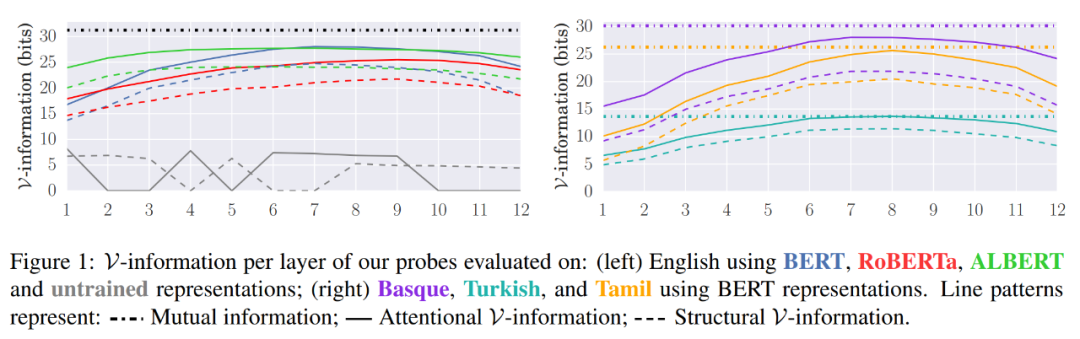
研究者还发现,句子中的几乎所有句法信息都可用于考虑中的基于 transformer 的模型。例如在英语中,他们发现信息量最大的层在 BERT、RoBERTa 和 ALBERT 中的 V 系数分别为 90%、82% 和 89%,具体如下表 1 所示。这意味着这些模型可以访问一个句子中约 85% 的句法信息。不过未训练的 BERT 表示并不适合这种情况。

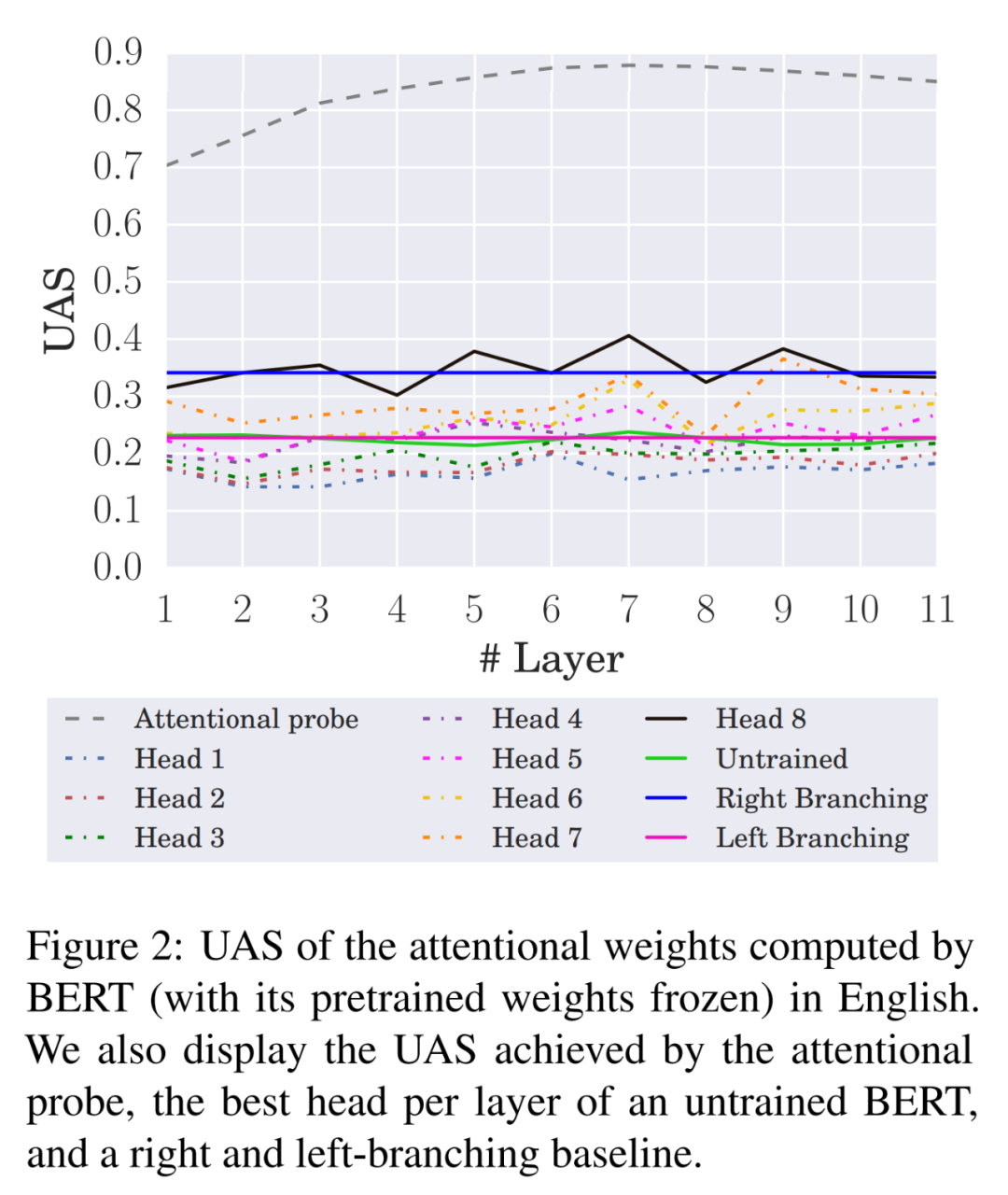
最后,研究者将 BERT 的注意力权重(通过其预训练的注意力头计算)直接插入到原文公式 (8) 并分析产生的未标记附件分数。英语相关的 BERT 结果如下图 2 所示。简言之,虽然注意力头可以使用大量的句法信息,但没有一个实际的头可以计算与句法树非常相似的权重。
但是,由于 BERT 有 8 个注意力头,因此可能以分布式方式使用句法信息,其中每个头依赖该信息的子集。
好了,关于架构瓶颈原则:用注意力probe估计神经网络组件提供多少句法信息就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “尔森”用心倾听大自然的神秘邀约
- “考生”硕士统考发布报名提醒 考生需及时自查,抓紧时间修改
- “合肥市”“柿柿如意,柿如破竹”…… 高三学子“花式解压”
- “肌肉”磁铁刺激疗法可“对齐”肌肉纤维
- “低价”第15个双11:电商巨头争夺“最低价”、取消预售、开放生态
- “犯罪嫌疑人”湖南新化砍伤一对夫妇的犯罪嫌疑人落网,4人涉嫌窝藏罪被批捕
- “中国移动”中移动市场详情:合作伙伴大会重要发言及发布、反诈、5G应用获奖
- “血液”简单的血液检查调整可使重症监护治疗更安全
- “南充市”落马公安局长收受财物1365万被判7年:悔称利欲熏心,“金钱大厦”瞬间倾覆一生毁灭
- “高粱”河南固始有执法人员带人偷高粱?当地回应:涉事人员为行政执法大队人员,正调查
- “发信息”特发信息今年上半年又亏损 还被立案调查 总经理伍历文怎么看?
- “隐私”Find N3 为用户隐私上锁
- “茅台”消费资讯 | 飞猪被曝泄露个人信息 茅台董秘称员工离职率只有万分之三
- “亿元”V观财报|“股价还在坑里”,东方雨虹董秘疑发800字小作文!律师提醒
- “产业链”《移动信息现代产业链健康指数体系》报告正式发布
- “注意力”别再「浪费」GPU了,FlashAttention重磅升级,实现长文本推理速度8倍提升
- “能力”中移信息技术中心陈国:能力中台服务4000多家客户 实现直接价值近300亿
- “产品”中国移动总经理董昕:共商产品发展新路 共拓信息服务蓝海
- “上海市”上海市互联网新闻信息服务单位许可信息(截至2023年9月30日)
- “产品”中国移动总经理董昕: 共商产品发展新路 共拓信息服务蓝海









