“模型”20B跨级挑战70B性能!国产开源大模型打造大模型新标杆
今天,很高兴为大家分享来自机器之心Pro的20B跨级挑战70B性能!国产开源大模型打造大模型新标杆,如果您对20B跨级挑战70B性能!国产开源大模型打造大模型新标杆感兴趣,请往下看。
9 月 20 日,上海人工智能实验室(上海 AI 实验室)与商汤科技联合香港中文大学和复旦大学正式推出书生・浦语大模型(InternLM)200 亿参数版本 InternLM-20B,并在阿里云魔搭社区(ModelScope)开源首发。同时,书生・浦语面向大模型研发与应用的全链条工具链全线升级,与 InternLM-20B 一同继续全面开放,向企业和开发者提供免费商用授权。
浪潮之上,大模型的应用价值日趋受到关注。正如历史上的任何一项新技术,其生命力终究要回归到是否可以广泛落地,为世界带来积极且真实的变化。在此背景下,上海 AI 实验室联合多家机构推出了中量级参数的
代码库链接:https://github.com/InternLM/InternLM
魔搭社区链接:https://modelscope.cn/organization/Shanghai_AI_Laboratory
自今年 6 月首次发布以来,书生・浦语已经历多轮升级,在开源社区和产业界产生了广泛影响。

书生・浦语 “增强版”:增的不只是量
相比于国内社区之前陆续开源的 7B 和 13B 规格的模型,20B 量级模型具备更为强大的综合能力,在复杂推理和反思能力上尤为突出,因此可为实际应用带来更有力的性能支持;同时,20B 量级模型可在单卡上进行推理,经过低比特量化后,可运行在单块消费级 GPU 上,因而在实际应用中更为便捷。
InternLM-20B 是基于 2.3T token 预训练语料从头训练的中量级语言大模型。相较于 InternLM-7B,训练语料经过了更高水平的多层次清洗,补充了高知识密度和用于强化理解及推理能力的训练数据。因此,在考验语言模型技术水平的理解能力、推理能力、数学能力、编程能力等方面,InternLM-20B 都有显著提升。
相比于此前的开源模型,InternLM-20B 的能力优势主要体现在:
优异的综合性能。InternLM-20B 具备优异的综合性能,不仅全面领先相近量级的开源模型(包括 Llama-33B、Llama2-13B 以及国内主流的 7B、13B 开源模型),并且以不足三分之一的参数量,测评成绩达到了 Llama2-70B 的水平。
强大的工具调用能力。InternLM-20B 拓展了模型的能力边界,实现了大模型与现实场景的有效连接。InternLM-20B 支持数十类插件,上万个 API 功能,在 ToolBench 评测集上获得了最佳结果,在与 ChatGPT 的竞赛中,胜率达到 63.5%。InternLM-20B 还具备代码解释和反思修正能力,为智能体(Agent)的构建提供了良好的技术基础。
更长的语境。通过多阶段训练拓展,InternLM-20B 支持 16K 语境长度,从而更有效地支撑长文理解、长文生成和超长对话。
更安全的价值对齐。相比于之前版本,InternLM-20B 在价值对齐上更加安全可靠。在研发训练的过程中,研究团队通过基于 SFT(监督微调)和 RLHF(基于人类反馈的强化学习方式)两阶段价值对齐,以及专家红队的对抗训练,大幅提高其安全性。当用户带着偏见提问时,模型能够给出正面引导。
全线升级的开源工具、数据体系。书生・浦语开源工具链全线升级,形成了更为完善的工具体系,其中包括预训练框架 InternLM-Train、低成本微调框架 XTuner、部署推理框架 LMDeploy、评测框架 OpenCompass 以及面向场景应用的智能体框架 Lagent。书生・浦语工具链将和开源数据平台 OpenDataLab 构成强大的开源工具及数据体系,共同为学术界和产业界提供全链条的研发与应用支持。

架构增强:深结构、长语境
过去一段时间,国内机构陆续开源了多个参数量为 7B 和 13B 规格的模型,在评测中也取得了不俗的成绩。但研究人员发现,这些模型在适配下游任务,尤其是对准确性和推理能力要求较高的任务时,还存在局限。为了更好地支持这些任务,业界呼唤一个中量级的开源模型,提供更强的理解、推理以及长文生成能力。
在相对有限的参数规模下,研究人员在架构设计时面临重要的取舍 —— 提高模型的深度还是宽度?通过广泛的对照实验,书生・浦语团队发现,更深的模型层数更有利于复杂推理能力的培养。因此在架构设计时,研究人员把模型层数设定为 60 层,超过 7B 与 13B 模型通常采用的 32 层或者 40 层设计;同时内部维度保持在 5120,处于适中水平。通过架构设计上的新取舍,InternLM-20B 在较高计算效率的条件下实现了复杂推理能力的显著提升。
InternLM-20B 还支持更长的语境长度。在训练过程中,模型的语境长度分阶段从 2K 拓展到 8K。在推理侧,基于 Dynamic NTK 技术,把模型推理可支持的语境长度进一步延展到 16K。长语境为模型的能力拓展,包括工具调用、代码解释以及反思修正等提供了更大的空间,成为支撑在 InternLM-20B 之上打造智能体(Agent)的关键技术基础。
综合性能增强:多个评测中领先
基于 OpenCompass 大模型评测平台,研究人员在涵盖语言、知识、理解、推理和学科能力等五大维度的 50 个主流评测集上,对 InternLM-20B 及相近量级的开源模型进行了全面测试比较。评测结果显示,InternLM-20B 在全维度上领先于开源 13B 量级模型,平均成绩不仅明显超越 Llama-33B,甚至优于被称为开源模型的标杆 Llama2-70B。
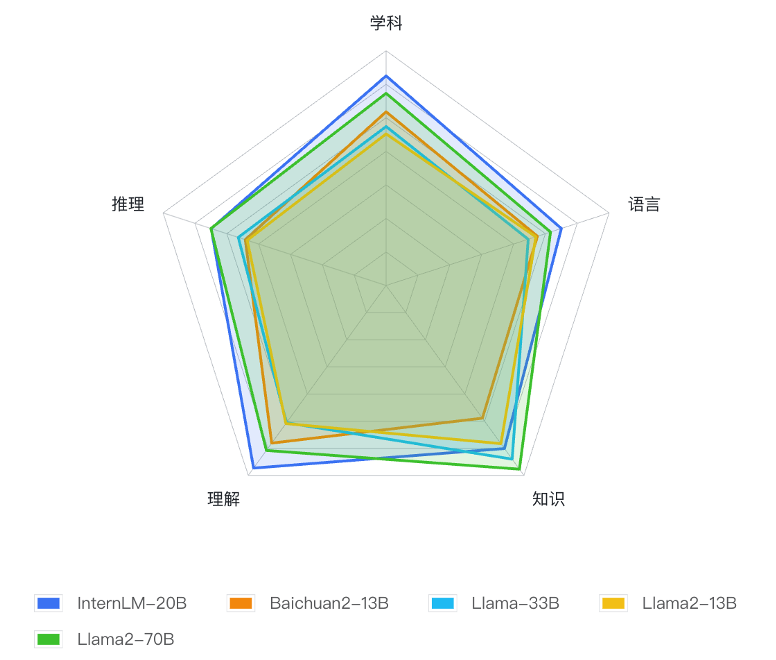
下表显示了 13B 及更高参数量的主流开源模型在各个维度上的平均成绩(红色字体为 13B-33B 量级范围内各能力维度最高评分)。InternLM-20B 在语言、知识学科综合评测上都超越 Llama2-70B,在推理能力评测上和 Llama2-70B 持平,而知识方面则仍有一定差距。但在上述所有维度上,InternLM-20B 都显著领先主流的 13B 量级开源模型。

下表在一些有重要影响力的典型数据集上比较了主流开源模型的表现(红色字体为 13B-33B 参数量级范围内各项测评最佳成绩):

评测结果显示,InternLM-20B 在 MMLU、C-Eval、AGIEval 综合性学科评测中成绩优异,在同量级开源模型中处于领先位置。MMLU 被普遍认为是评价一个语言模型综合能力的关键指标,InternLM-20B 在 MMLU 上取得 62.05 的成绩,接近 Llama-65B 的水平;而在包含中文学科考试的 C-Eval 和 AGIEval 上,InternLM-20B 的表现也明显超过了 Llama2-70B。
知识问答评测如 BoolQ、TriviaQA、NaturalQuestions 等,主要评价模型对于事实性知识的掌握能力,在此维度上,InternLM-20B 的表现超越 13B 模型,与 Llama-33B 各有千秋,但相比于 Llama-65B 或者 Llama2-70B 仍有一定差距。
CMRC、CSL、RACE 分别为面向百科知识、科技文献以及学生阅读理解的评测集,而 XSum 则是挑战性的文献摘要评测 —— 上述评测均为考察大模型理解能力。在理解能力维度,InternLM-20B 表现突出,全面超越包括 Llama2-70B 在内的各个量级的开源模型。
推理,尤其是复杂推理,是语言模型目前面临的常见难题,也是模型能否支撑实际应用的关键能力。上表中所列 WinoGrande、GSM-8K、PIQA、BigBench-Hard(BBH)分别考察模型在常识推理、数学推理、物理相关推理以及有挑战性的综合推理方面的能力。InternLM-20B 均获得明显超越主流的 13B 开源模型的成绩,在 WinoGrande、GSM8K 和 PIQA 评测上已非常接近 Llama-65B 此类重量级模型的推理能力水平。
InternLM-20B 的编程能力也有显著提升。在 HumanEval 和 MBPP 两个典型评测集上,全面超越了主流 13B 开源模型、Llama-33B 和 Llama-65B,接近 Llama2-70B 的水平。
在 HuggingFace 最新公布的 Open LLM Leaderboard 评测榜单上,InternLM-20B 在参数量 60B 以下基模型中平均成绩领先,也超过了 Llama-65B。

总体而言,InternLM-20B 在综合能力上全面领先于 13B 量级的开源模型,在评价推理和编程能力的多个评测集上接近甚至超越 Llama-65B,在中文相关的评测上普遍超越 Llama2-70B。
调用工具能力增强:不会也能学
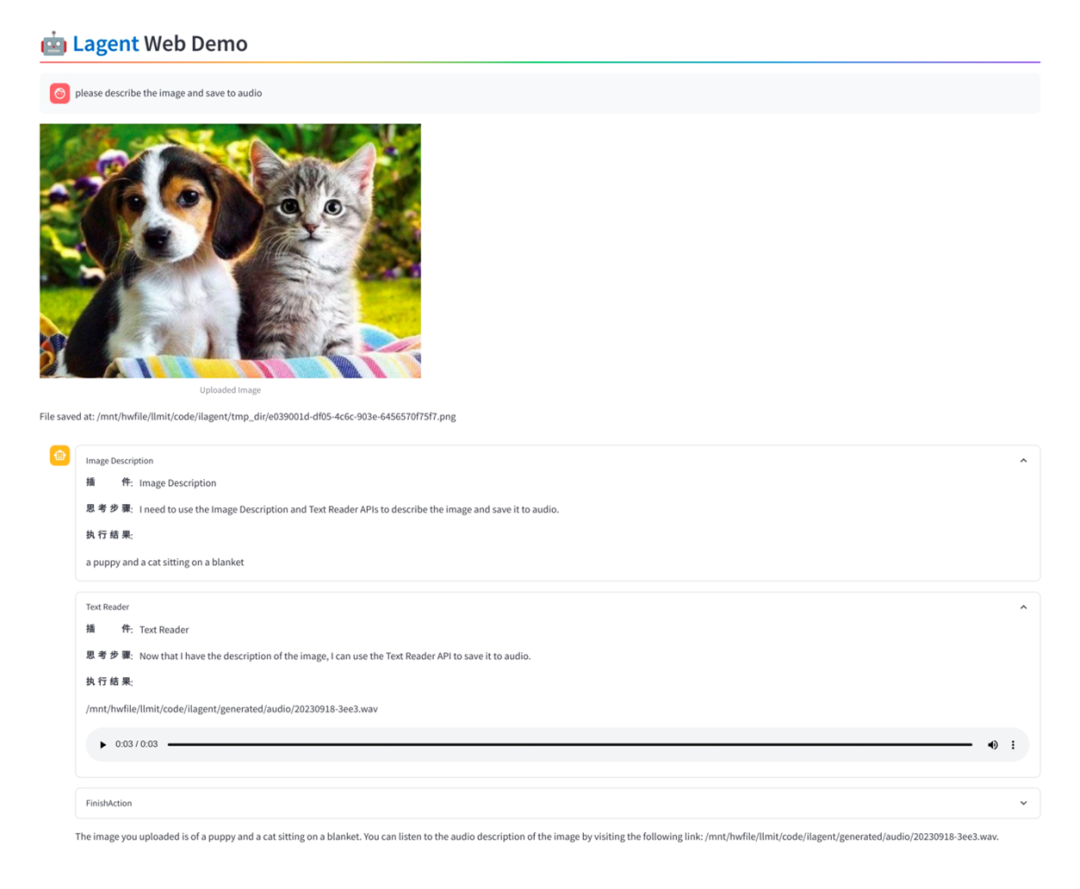
工具调用是拓展大语言模型能力边界的重要手段,也是 OpenAI 近期推出大模型的重点特性之一。InternLM-20B 对话模型支持了日期、天气、旅行、体育等数十个方向的内容输出及上万个不同的 API。
在清华大学等机构联合发布的大模型工具调用评测集 ToolBench 中,InternLM-20B 和 ChatGPT 相比,达到了 63.5% 的胜率,在该榜单上取得了最优结果,表现出强大的工具调用能力。

InternLM-20B 模型还展现出一定的零样本泛化能力,对于模型在训练过程中并没有学习过一些工具,InternLM-20B 也能根据工具描述和用户提问来调用工具完成任务。例如给模型提供一些 AI 工具,模型可以自己进行规划和推理,完成用户的问题。
价值观增强:更安全的开源模型
更贴合人类价值观的大语言模型,才有可能更好地充当 “人类助手” 的角色。InternLM-20B 在迭代过程中加入了大量符合人类价值观的数据,研究团队组织相关领域专家对模型进行了多轮红队攻击,大幅提升其安全性。
当用户向 InternLM-20B 提出带有偏见的问题时,它能够识别出不安全因素,并在回答中给出正确的价值引导。

对话能力增强:语境长度达到 16K
InternLM-20B 在训练阶段的语境长度分阶段拓展到了 8K,同时通过 Dynamic NTK 等手段将推理时的语境长度拓展到了 16K。基于 16K 的语境长度,InternLM-20B 可以有效支持长文理解、长文生成和超长对话。
下面一个例子展示了 InternLM-20B 的长文理解能力:让大模型阅读某知名咖啡品牌的最新新闻,模型能够准确回答提出的三个问题。

InternLM-20B 还具备为长篇论文和报告进行准确摘要提取的能力。研究人员向模型输入经典论文 ResNet 的 Introduction 章节,它能较好地写出摘要,准确概括了 ResNet 的核心思想和实验效果。

全链条工具体系再巩固,全面升级
今年 7 月,上海 AI 实验室与商汤科技联合高校在正式发布书生・浦语的同时,在业内率先开源了覆盖数据、预训练、微调、部署和评测的全链条工具体系。历经数月升级,书生・浦语全链条开源工具体系巩固升级,并向全社会提供免费商用。
数据 - OpenDataLab 开源 “书生・万卷” 预训练语料
书生・万卷是上海 AI 实验室开源的多模态语料库,包含文本数据集、图文数据集、视频数据集三部分,数据总量超过 2TB。目前,书生・万卷 1.0 已被应用于书生・多模态、书生・浦语的训练。通过对高质量语料的 “消化”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出优异性能。
预训练 - InternLM 高效预训练框架:除大模型外,InternLM 代码库开源了预训练框架 InternLM-Train。深度整合 Transformer 模型算子提升了训练效率,并提出了独特的 Hybrid Zero 技术,实现了计算和通信的高效重叠,大幅降低训练过程中的跨节点通信流量。得益于极致的性能优化,实现了千卡并行计算的高效率,训练性能达行业领先水平。
微调 - InternLM 全参数微调、XTuner 轻量级微调:InternLM 支持对模型进行全参数微调,支持丰富的下游应用。同时,低成本大模型微调工具箱 XTuner 也在近期开源,支持多种大模型及 LoRA、QLoRA 等微调算法,通过 XTuner,最低仅需 8GB 显存即可对 7B 模型进行低成本微调,20B 模型的微调,在 24G 显存的消费级显卡上就能完成。
部署 - LMDeploy 支持十亿到千亿级参数语言模型的高效推理:LMDeploy 涵盖了大模型的全套轻量化、推理部署和服务解决方案,支持了从十亿到千亿级参数的高效模型推理,在吞吐量等性能上超过 FasterTransformer、vLLM 和 Deepspeed 等社区主流开源项目。
评测 - OpenCompass 一站式、全方位大模型评测平台:OpenCompass 是上海 AI 实验室开源的大模型评测平台,构建了包含学科、语言、知识、理解、推理五大维度的评测体系,支持超过 50 个评测数据集和 30 万道评测题目,支持零样本、小样本及思维链评测,是目前最全面的开源评测平台。自 7 月发布以来,受到学术界和产业界广泛关注,目前已为阿里巴巴、腾讯、清华大学等数十所企业及科研机构广泛应用于大模型研发。
应用 - Lagent 轻量灵活的智能体框架:书生・浦语团队同时开源了智能体框架,支持用户快速将一个大语言模型转变为多种类型的智能体,并提供典型工具为大语言模型赋能。Lagent 开源框架支持 InternLM、Llama 及 ChatGPT 等大语言模型,并集合了 ReAct、AutoGPT 及 ReWoo 等多种类型的智能体能力。在 Lagent 的加持下,这些智能体可调用大语言模型进行规划推理和工具调用,并可在执行中及时进行反思和自我修正。
基于书生・浦语大模型,上海 AI 实验室已发展出更丰富的下游应用,将于近期陆续向学术界及产业界分享。
面向大模型掀起的新一轮创新浪潮,上海 AI 实验室致力于以原始创新引领技术进步,持续打造综合能力更强大的基础模型,构建更完整易用的全链条工具体系,并坚持通过开源开放、免费商用,全面赋能整个 AI 社区生态的繁荣发展,帮助企业和研究机构降低大模型的开发和应用门槛,让大模型的价值在各行各业中绽放。
全链条工具体系开源链接:
“书生・万卷” 预训练语料:https://github.com/opendatalab/WanJuan1.0
InternLM 预训练框架:https://github.com/InternLM/InternLM
XTuner 微调工具箱:https://github.com/InternLM/xtuner
LMDeploy 推理工具链:https://github.com/InternLM/lmdeploy
OpenCompas 大模型评测平台:https://github.com/open-compass/opencompass
Lagent 智能体框架:https://github.com/InternLM/lagent
好了,关于20B跨级挑战70B性能!国产开源大模型打造大模型新标杆就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “考生”下半年自考即将开始 省考试院发出温馨提示
- “父亲”父亲的眼神杀
- “这是”自内耗到自洽
- “大桥”G3铜陵长江公铁大桥先导索过江
- “某甲”父亲被羁押继母要离婚,未成年女儿谁来抚养?法官多方努力,难题解决了!
- “亚马逊”哪些以色列芯片公司已被美国企业收购?
- “结构”结核杆菌致病机制获揭示
- “装修”装修公司老板明知公司亏损仍吸引客户签合同,骗取上百人700余万,被判11年
- “射电”穿越80亿光年的快速射电暴源于一场“星系交通事故”
- “必胜客”必胜客最黑暗的料理来了
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等
- “能力”浙江移动助力科技反诈,护好民众“钱袋子”
- “融资”国内AI大模型赛道火热,大厂积极跟投布局
- “模型”在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了









