“机器人”当机器人遇上大模型,“智能”的齿轮开始转动 | 榕汇产学研研讨
今天,很高兴为大家分享来自高榕资本的当机器人遇上大模型,“智能”的齿轮开始转动 | 榕汇产学研研讨,如果您对当机器人遇上大模型,“智能”的齿轮开始转动 | 榕汇产学研研讨感兴趣,请往下看。
来源:高榕资本
具身智能(Embodied Intelligence)概念自1950年被图灵提出以来,经历了漫长的多学科发展与融合。随着生成式AI和大模型进阶,唤醒人们对具身智能的更多期待,学术界、科技公司亦积极投入。
概括定义,具身智能指的是通过自身身体体验来产生智能的能力。其中,AI和机器人的深度融合是重要趋势——机器人成为大模型的重要载体;大模型也重构了机器人的开发流程,实现通用场景、多任务、快开发的模式。
更远的未来,通用机器人有望彰显出高度智能和实用价值——不仅具有感知、理解、推理、决策等能力,也能与物理世界真实互动、高效执行指令和任务,这将为人类的智能生活带来更大的想象空间。
当然,具身智能距离真正落地仍有诸多挑战,涉及机器人本体、算法、数据、计算等维度。
近日,高榕资本榕汇举办『具身智能』产学研线上研讨会,来自科研界、人工智能计算企业和人形机器人厂商的专家,从各自视角分享在具身智能领域的前沿探索实践。
以下为部分嘉宾分享精华(经整理):


今天很多具身智能体已经在某些特定场景有非常强的能力,乃至成为“专家”;但我们真正期待的具身智能体,可能是一个通用机器人(general robot),我们希望他们可以在1000个场景(工厂、实验室、厨房等)里去解决1000种任务,并且要处理各种各样的物体。
但是为何绝对的通用机器人仍然没有到来,我们依然无法让机器人实现这样的泛化能力?举个例子,一个机器人打开冰箱,会看到各种各样的食物、饮料瓶等等,我们在训练场景中很难涉及如此复杂的物体,更不用说真实世界的场景更为复杂。
目前我们从实际遇到的问题中抽象出具身智能三个泛化需求:视觉外观(Visual Appearance)、六维位姿(6D Poses)以及物体性质(Object Types),对应地我们也提出了一些解决方案。
1)视觉外观泛化
我们知道,在计算机视觉领域,ImageNet作为图形分类基准数据集对这一领域的发展起到了重要的助推作用,那么我们就想,是否可以搭建一个面向具身智能视觉泛化的强化学习基准平台?
因此我们推出RL-ViGen,在这一平台上,具身智能算法可以进行比较和测评,初步验证谁能够泛化到足够多样的场景,进而有潜力从实验室走进千家万户。
目前RL-ViGen集成了丰富的任务类别,包括机械臂操作、自动驾驶、灵巧手操作、四足或双足机器人,以及室内外导航等。更进一步,RL-ViGen也提供了多个泛化类型,包括外观(颜色、纹理等)、相机视角、光照、结构和本体。

此外,我们也提出一种基于预训练图像编码器的可泛化视觉强化学习方法(简称PIE-G)。
以往我们在对具身智能体进行预训练和测试时,输入不同视觉场景会导致模型泛化能力出现显著差异。如何在保证训练效率的同时,训练出更为鲁棒和泛化性能更强的模型?PIE-G直接利用ImageNet的预训练模型生成的表征,嵌套在视觉强化学习算法里。通过使用early layer和更新Batch Norm的统计参数,进一步突破智能体泛化能力瓶颈。

PIE-G在泛化性能上比现有方案平均有55%的提升,最高可达127%。可视化的角度来看,无论是在MetaWorld还是自动驾驶模拟器CARLA中,PIE-G都可以应对各种背景的变化。
2)类内物体和位姿泛化
找到对应关系是实现6D位姿泛化的关键要素。所谓位姿泛化,举个例子,作为人类如果我们学会使用一把刀,那么也就会使用其他的刀,原因是能够识别菜刀的关键特征点(刀柄、刀尖等)。也因此,为了实现位姿泛化,我们需要找到关键点的对应关系。
在计算机视觉领域已经有很多成熟的方法,例如利用无监督方式(如KeypointDeformer)找到物体的关键特征点。但是在现实世界中,受到低质量点云、位姿旋转等因素影响,这些特征点比较难真正发挥作用。
我们提出了一个Teacher-Student Framework。利用经典“教师”网络架构PointNet++去提取一个物体的特征,基于无监督方式得到一系列关键点,“学生网络”再去模仿学习关键点(有监督方式),且对于任何旋转输入都可以保持同样的输出。
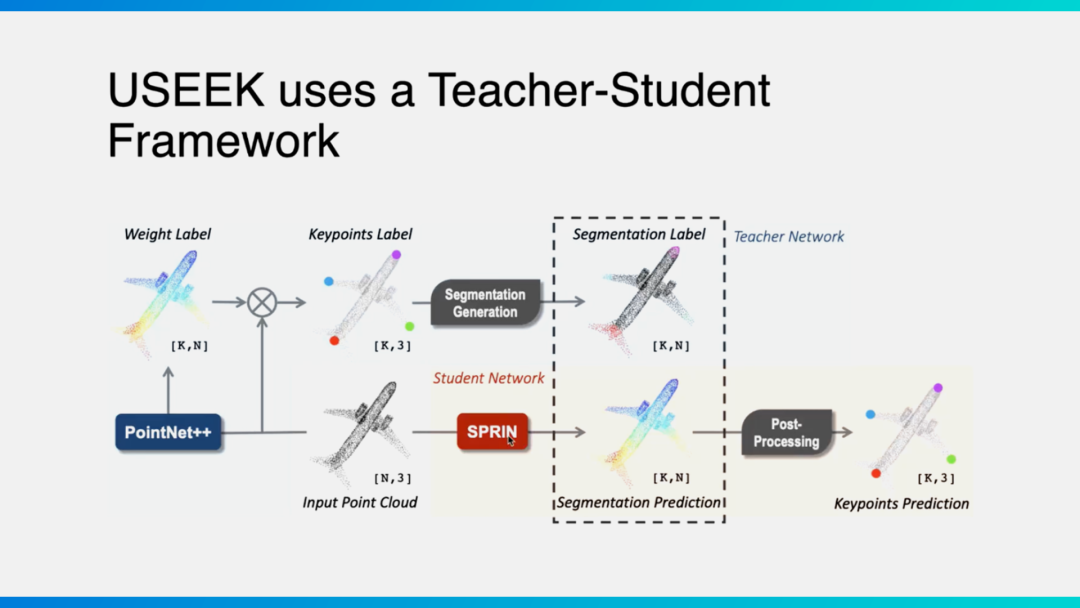
这一框架,让我们能够找到类内物体关键点的对应关系,进而完成类内物体任何位姿的泛化。
3)多种物体泛化
再进一步,具身智能如何实现多种物体的泛化?目前一个初步的尝试是,可以设计特定机器人构型,比如我们从零构建的触觉控制机器人ArrayBot。
ArrayBot采取分布式的结构,如同一个阵列,通过读取物体的触觉信息,无需考虑重力和视觉干扰等问题;此外基于强化学习,我们在仿真环境下对机器人进行了大规模训练,得出的策略可以直接用以操作不同的现实物体。

ArrayBot有望在工业场景中作为智能传送带,或家庭场景中的智能桌子。当然ArrayBot只是其中一种构型尝试,其他诸如软体机器人等构型也有望解决多种物体泛化的问题。
相关论文:
RL-ViGen: A Reinforcement Learning Benchmark for Visual Generalization, 2023.
USEEK: Unsupervised SE(3)-Equivariant 3D Keypoints for Generalizable Manipulation, 2023.
ArrayBot: Reinforcement Learning for Generalizable Distributed Manipulation through Touch, 2023.


具身智能有几个关键特点:以第一视角为基础,使得个体能够理解环境、做决策,最重要的是能够与环境互动、从互动中学习知识,进而执行底层动作。与此同时,具身智能的任务也是非常广泛的,包括视觉导航、桌面操作、物品摆放、具身问答、移动操作、指令跟随等等。
因此,我们尝试去打造一个能够实现广泛任务的通用具身智能系统,他一方面有机会具身地完成各种各样的任务;对于现有机器人来说,接入之后可以在智能层级上进行全面的提升。
针对通用具身智能系统目前面临的几大核心挑战,我们尝试提出了若干解决方案。
1)第一视角下的具身认知
以往计算机视觉,更多是第三人称视角的“感知”能力;第一人称视角的“认知”能力,除了能够看到和理解物体的类别、位置、轮廓等,还可以学会如何与对象交互,具有可操作性。比如在开抽屉时,更关注把手等可操作性的部分。
也因此,我们需要一个具备第一视角细粒度和强交互性的数据集来支持训练。为此,我们打造了EgoCOT数据集。这一数据集包含了2900多个小时的细粒度视频文本标注数据。数据通过第一人称视角采集,并且在非常丰富的场景下与各种各样的物体进行交互。
2)通用决策规划
在构建认知系统之后,具身智能还需要在开放世界应对复杂任务、进行决策和规划,那么需要多模态通用的知识库。为此,我们推出了国内首个多模态具身智能大模型EmbodiedGPT。EmbodiedGPT具备具身规划的能力,根据视觉输入可以输出step by step的任务规划;此外还拥有Video Capture、Video Q&A乃至多轮对话的能力。

EmbodiedGPT基于ViT视觉模型和LLaMA语言模型,更加匹配高校和中小企业的需求。从视觉到语言端,我们设计了Embodied-Former和Language Mapping去进行两个模态的衔接。比较独特的是,我们通过可学习的Embodied Queries和视觉特征以及文本特征之间的attention机制,能够提取出与当前任务最相关的特征信息,并将其通过language mapping layer传递给语言模型。
此外模型也支持代码生成,可以直接生成step by step的指令,并且按部就班执行。
目前这一模型在一些通用场景已经显示出应用潜力,比如视觉导航、机械臂真机实验等等。
3)底层技能学习
真正的具身智能系统,我们还希望能够以非常高的学习效率掌握新的技能,并且迁移和泛化到新的场景与任务之上。为此,我们主要基于强化学习,研究高效策略学习、知识迁移、多场景泛化等算法。
相关论文:
EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought, 2023.


1)软硬件平台加速机器人开发效率
NVIDIA Isaac是端到端的机器人开发平台,包括仿真平台、算法开发模块,以及中间件和底层加速库。无论是从0到1搭建机器人,还是实现算法操作,亦或快速补齐机器人开发应用中的模块,都有加速软件库去支持,提升机器人、尤其是AI机器人应用开发的效率。
数据对于AI机器人的开发至关重要,但很多场景的数据采集会遇到限制。Isaac Sim是基于Omniverse的机器人数字孪生仿真平台,可以帮助机器人在虚拟环境下生成标注好的数据集。在平台中,可以通过3D建模打造数字孪生环境,随机化修改环境,并通过replicator生成虚拟数据集,作为数据资产用于模型训练、数据回放等等。Isaac Sim对光线追踪、物体材质、机器人等描述都可以精准呈现,达到一个数字孪生级别的仿真平台。
2)见证大模型更多部署在机器人端侧
面对大模型和通用机器人的进阶,我们认为,机器人最终有望变成大模型推理的最佳载体,相信未来会看到更多大模型部署在机器人端侧的用例。在那个时间点,很多移动的机器人都会拥有大模型交互的能力,也是具身智能的体现。
这也对计算提出更高要求。作为人工智能计算平台,我们希望最前沿的核心技术能够应用在NVIDIA的平台,并基于这些技术推出更好的硬件架构和软件基础架构,承载对算力越来越强的需求,并基于更友好的软件生态实现兼容。此外也希望在商业化落地方面,领先的行业客户能够给予更多反馈,帮助开发者和用户更轻松实现落地。
场景和应用角度,在可预见的范围内,我们都有机会见证机器人快速爆发增长。比如人形机器人可以在仓储物流行业提升效率,也可以完成诸如排爆、电力巡检等危险工作。就像“特种兵”,成为人类的朋友和助手。
具身智能距离落地仍有诸多艰难挑战,需要长期的技术积累和研发投入。也因此,需要产学研通力合作、汇聚成河,加速这一技术走进我们的生活。

好了,关于当机器人遇上大模型,“智能”的齿轮开始转动 | 榕汇产学研研讨就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “考生”下半年自考即将开始 省考试院发出温馨提示
- “父亲”父亲的眼神杀
- “这是”自内耗到自洽
- “大桥”G3铜陵长江公铁大桥先导索过江
- “某甲”父亲被羁押继母要离婚,未成年女儿谁来抚养?法官多方努力,难题解决了!
- “亚马逊”哪些以色列芯片公司已被美国企业收购?
- “结构”结核杆菌致病机制获揭示
- “装修”装修公司老板明知公司亏损仍吸引客户签合同,骗取上百人700余万,被判11年
- “射电”穿越80亿光年的快速射电暴源于一场“星系交通事故”
- “必胜客”必胜客最黑暗的料理来了
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “液态”我国学者构建液态金属磁性微型软体机器人,可用于临床医学
- “中国移动”中国移动高同庆:持续推进5G走进行业、行业拥抱5G,形成双动力良性循环
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “人类”有了GPT-4之后,机器人把转笔、盘核桃都学会了
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “三星”畅享智能互联 三星Galaxy Tab S9 FE即将开售
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手









