“药物”科学家获取特定免疫药物设计通用法则,迎接数据驱动药物发现的新拐点
今天,很高兴为大家分享来自DeepTech深科技的科学家获取特定免疫药物设计通用法则,迎接数据驱动药物发现的新拐点,如果您对科学家获取特定免疫药物设计通用法则,迎接数据驱动药物发现的新拐点感兴趣,请往下看。
来源:DeepTech深科技
赵伟安博士是加州大学尔湾分校的终身正教授,他在包括 Science Translational Medicine、Nature Biomedical Engineering、Nature Communications、PNAS 等知名期刊上共同发表了 100 余篇论文,入选斯坦福全球前 2% 顶尖科学家。
他获得过包括《麻省理工科技评论》“35 岁以下科技创新 35 人”(TR35)全球,世界经济论坛新领军者奖,美国国立卫生研究院的创新者奖,以及加州大学尔湾分校的年度创新者奖在内的诸多奖项。
赵伟安在哈佛医学院、布里格姆女子医院、麻省理工学院、麦克马斯特大学和山东大学接受了生物工程师和制药科学家的训练。此外,他还是连续创业者,目前赵伟安博士在 Aureka 生物科技公司担任 CEO,全职带领着一支充满激情的创业者和创新者团队,希望通过数字化、智能化药物的发现和开发,来改变制药行业。
 图丨赵伟安(来源:赵伟安)
图丨赵伟安(来源:赵伟安)传统的药物开发主要基于经验试错,过程中存在诸多问题。从时间和资金成本上看,其过程非常昂贵且耗时。一种药物从开发到上市平均需要 8-10 年,平均耗资约 15 亿美元[1]。尤其是对于大分子药物的开发,这个过程的风险甚至更大。
在药物研发过程中,一旦发现候选药物有毒性或副作用,研究可能被迫中止,这不仅会导致公司不得不放弃该项开发,还会浪费巨大的人力和物力成本。此外,新型药物所面临的问题则更为复杂,如双特异性抗体(双抗)、抗体偶联药物(antibody-drug conjugate,ADC)、T 细胞受体嵌合型 T 细胞(T cell receptor-engineered T cell therapy)等。
这些药物的开发需要对大量分子进行合成和表征,这使下游实验的过程变得极其繁重。面对传统药物开发面临的诸多挑战,迫切需要一种高效、低风险、高安全的新范式。
Aureka 是一家结合 AI 技术与高通量数字生物技术,专注于蛋白设计和免疫药物发现的平台型生物科技公司。该公司尝试利用 AI 和高通量技术来改变上述情况,以提高药物研发的效率、降低研发成本和风险、填补未被满足的临床需求,让更多有效的治疗方案能早日惠及患者。
以一款经典双抗药物 Hemlibra 的开发为例,这款双抗药物的开发需要对数万个分子一一进行合成和表征,而 Aureka 则可以将同样量级项目的合成和表征的时间缩短到几周之内。
赵伟安表示:“可以将我们具有自我进化能力的预测模型想象成一个类似于 ChatGPT 的模型,这种模型的底层都是由数据驱动的。我们的方法也是这样,模型会随着我们的数据平台生成的数据进行迭代,从而反向优化生物模型和预测模型,使其不断完善,最终提高预测和设计的能力。”
从数年到几周时间的对比,具体是如何做到的?Aureka 公司又是如何将 AI 技术融入到药品研发中的呢?

实现获取特定免疫药物设计的通用法则
传统的免疫药物(比如双特异性抗体)研发方法由于基于低通量(比如微孔板)的经验试错法,整个流程周期长、成本高、可表征的分子数量少,且成功率低。另外,目前市场上的免疫抗体发现多数以结合筛选为主, 但值得关注的是,大多数有结合力的抗体不具备与药物机制对应的功能(比如,激活细胞表面受体)。
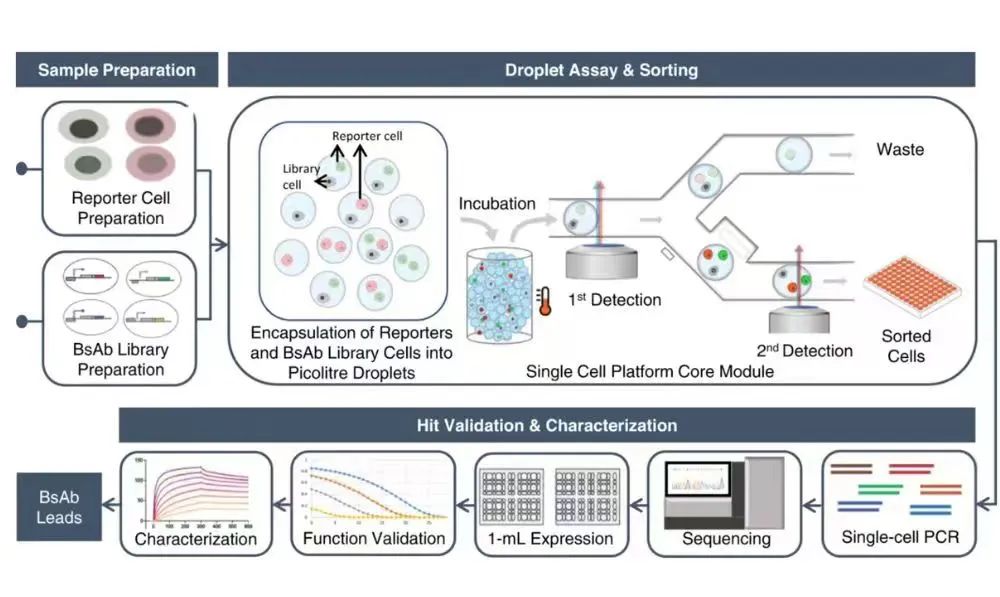 图丨解码双抗多变量同时设计和优化的通用法则(来源:Communications Biology)
图丨解码双抗多变量同时设计和优化的通用法则(来源:Communications Biology)Aureka 曾提出一种双特异性抗体的快速研发方法,相关论文发表在 Nature 子刊 Communications Biology 上[2]。该方法基于液滴微流控的单细胞研究平台,而平台的独特优势是可以同时兼顾高通量和高内涵,通过使用单细胞组合文库,实现对大量、多样性候选药物在原生环境下的直接功能化表征,从而在双抗研发效率方面比传统方法提高了几个数量级。
同时,每一个实验可以产生几百万组数据,涵盖候选药物的基因序列、功能、高内涵细胞图像、成药性等。赵伟安指出,“这些内部产生的大数据与我们 AI 的药物设计平台相互赋能、迭代,从而在领域内首次实现获取特定免疫药物设计的通用法则。”
据了解 ,Aureka 公司最早的核心技术起源是高通量单 B 细胞功能筛选技术。以双抗平台为例,Aureka 在较短时间内就完成了制备、表达、筛选到表征的整个流程,从数百万种可能的双抗组合中快速找到了超过 100 个具有功能性的分子。现在,基于这个项目的合作管线已经进入了临床前研究阶段。
在该技术基础上,他们还引入了两项创新技术以进一步增强团队的研发能力。第一项是基于合成生物学的亲和力和功能优化技术,这项技术可以帮助在上游阶段进行更精确、高效的分子合成和设计。
第二项创新技术则是 Aureka 的人工智能平台。该平台可以帮助分析和整合每个月从高通量功能实验筛选和合成生物学平台中产生的,涵盖基因、序列、细胞表型图像、功能等的 PB 级多模态数据,从而揭示新的药物发现或药物设计原则。
赵伟安表示,这两项创新技术与 Aureka 此前的高通量单 B 细胞功能筛选技术相辅相成,共同构成了 Aureka 公司的技术体系。借助这三项技术的融合,目前已经取得了一些初步的实验成果,并且超出了最初的设想。
据了解,目前,Aureka 已与多家跨国大型药企进行试点项目。“通过这些试点项目,验证了 Aureka 的技术平台的有效性,并且取得了一些超出预期的结果,这也进一步增强了我们对我们技术平台未来潜力的信心。”他说。
目前,Aureka 从三个方面将 AI 和高通量生物数据产生平台结合进行药物研发,包括生成技术、预测技术以及干湿结合的迭代模式。将 AI 技术融入药物研发过程中的核心主要体现在以下三方面:
首先,生成技术部分。据悉,Aureka 团队开发了一种生物启发式的蛋白语言模型,通过利用自主产生的高质量免疫数据进行模型微调,这种方法可以帮助研究者基于结构和功能来设计特定的抗体和抗体库。“这种设计方法结合独特的高通量数字生物平台,可以帮助解决在难成药靶点如 GPCR 的苗头化合物发现、功能优化和亲和力成熟等方面的问题。”赵伟安说。
其次,预测模型的建立。Aureka 团队结合自主产生的高通量功能数据开发了一些模型来进行蛋白建模,包括性质预测和结构建模。这些预测模型可以帮助从药效学的角度去降低毒性或免疫源性风险。与此同时,更好地从结构层面理解双抗、ADC 与其他分子在体内的相互作用方式。
再次,模型的自我进化能力。Aureka 的模型库是一种持续自我进化的系统,随着其数据平台产生的新数据,模型会进行自我迭代并优化。
赵伟安表示,通过 AI 技术的引入和优化,可以大幅度提高药物研发的效率、降低研发过程中的风险,真正地推动药物发现模式从试错模式走向数据驱动模式,实现数字赋能产业。

或将推动药物开发的进程
Aureka 的核心技术可应用于各种免疫治疗和合成生物学领域。目前,该公司主要聚焦在一些常见的免疫药物形式,如单抗、双抗、TCR-T、CAR-T 、ADC 等及难成药靶点如 G 蛋白偶联受体的攻坚上。在未来,该公司还计划将其技术应用范围扩大到包括多肽,迷你蛋白和酶的设计等合成生物学领域。
从当下来看,大分子药物在药物研发中的市场价值已经显示出逐渐超过小分子药物的趋势。“我们相信,Aureka 的技术能够帮助药物研发者更快、更好地发现新的免疫药物,从而更好地理解和解析生物系统,有效治疗一些罕见的、难以治疗的疾病,实现治病救人的目标。大分子药物领域的市场潜力非常大,随着技术的发展和应用,预期其市场价值将会持续增长。”他表示。
未来,Aureka 希望数字生物学和人工智能平台的应用能带来革命性的改变,进而极大地推动药物开发的进程。
可以预期的是,该平台在未来几年内将能替代许多传统的免疫药物发现过程中繁琐、耗时的环节,如亲和力成熟、人源化以及双抗错配等。赵伟安表示,通过运用 AI 技术,我们可以使得这些步骤的效率大大提升,同时减少研发中的风险和成本。
更长远的来看,该公司的目标是创造一种全新的药物发现范式。这个范式将构建一个通用的药物发现智能系统,通过不断迭代数据和模型,针对一些靶点实现真正地“一键式”药物生成(de novo design)。这将极大地提高药物研发的效率,缩短药物上市的时间,并提高药物疗效,使患者能更快地获取到治疗。
谈起对该平台未来的期待,赵伟安表示:“我们期望当获取的数据量和质量达到一定的临界点时,这个平台不仅能帮助解决药物研发的问题,还能解决更广泛的生命科学问题。未来,通过平台将深入了解生命科学的奥秘,以此更深入地理解各种疾病、更有效地治疗疾病。”
 支持:张智
支持:张智参考资料:
1.https://www.lshtm.ac.uk/newsevents/news/2020/average-cost-developing-new-drug-could-be-15-billion-less-pharmaceutical
2.Segaliny, A.I., Jayaraman, J., Chen, X. et al. A high throughput bispecific antibody discovery pipeline. Communications Biology 6, 380 (2023). https://doi.org/10.1038/s42003-023-04746-w
运营/排版:何晨龙
好了,关于科学家获取特定免疫药物设计通用法则,迎接数据驱动药物发现的新拐点就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “考生”下半年自考即将开始 省考试院发出温馨提示
- “父亲”父亲的眼神杀
- “这是”自内耗到自洽
- “大桥”G3铜陵长江公铁大桥先导索过江
- “某甲”父亲被羁押继母要离婚,未成年女儿谁来抚养?法官多方努力,难题解决了!
- “亚马逊”哪些以色列芯片公司已被美国企业收购?
- “结构”结核杆菌致病机制获揭示
- “装修”装修公司老板明知公司亏损仍吸引客户签合同,骗取上百人700余万,被判11年
- “射电”穿越80亿光年的快速射电暴源于一场“星系交通事故”
- “必胜客”必胜客最黑暗的料理来了
- “中国科协”2023重大科学问题、工程技术难题和产业技术问题发布
- “阿片”美国每6.5分钟就有一人死于阿片药物过量,三年以来致死人数翻两番
- “集团”独家:中移动技术部总经理陈洪涛上任有数月 系技术型干部突出代表
- “长江”28项获奖,长江科学技术奖拟授奖名单公示
- “受害者”微软宣布破获一桩“技术支持”钓鱼诈骗案:5 年 2000 余人受害
- “模型”对话智谱AI CEO张鹏:中国通用大模型,做行业生意|顺为系
- “技术”人邮时评丨5G瘦身,RedCap加速制造业数字化最后一公里进程
- “异议”2023年度贵州省科学技术奖受理项目公示
- “阿联酋”Etisalat by e&首席技术信息官Khalid Murshed:5G加速发展,使能更大商业成功
- “模型”三六零获评2023年度软件和信息技术服务名牌企业









