“商汤”类ChatGPT新玩家「商量」入场,商汤如何「日日新」?
今天,很高兴为大家分享来自雷锋网的类ChatGPT新玩家「商量」入场,商汤如何「日日新」?,如果您对类ChatGPT新玩家「商量」入场,商汤如何「日日新」?感兴趣,请往下看。

作者 | 李梅
编辑 | 岑峰
在魔都的东南角临港新片区,商汤科技人工智能计算中心AIDC在2022年启动运营,楼宇俯瞰宛若芯片。自ChatGPT以来,国内各家对大模型的追逐马不停蹄,继百度「文心一言」、阿里「通义千言」之后,昨日下午,商汤终于在AIDC亮相了其自研千亿参数中文语言大模型——「商量 SenseChat」。
而商汤这次拿出的,不止一个类ChatGPT。在技术交流日现场,商汤科技CEO徐立展示了商汤「日日新 SenseNova」大模型研发体系,以及文生图、数字人视频生成、3D内容生成等一系列AIGC应用,演示期间惊叹和掌声此起彼伏。
 商汤科技CEO徐立展示「日日新」大模型体系
商汤科技CEO徐立展示「日日新」大模型体系回过头看商汤在过去几年大模型研发和算力基础设施上的积累,观赛者们惊觉:在这一波大模型的竞技场上,商汤原来早有准备,出场迅速,且武艺绝佳。
—— 01 ——
商汤,出场
「苟日新、日日新、又日新」,这句话出自《礼记·大学》中汤之《盘铭》,也是商汤「日日新SenseNova」大模型体系的取名由来,承载了今天我们对大模型快速迭代、走向通用人工智能(AGI)的期待。
目前,商汤已经打造了视觉、自然语言、AIGC多个方向的AI大模型,正在以多模态大模型结合决策智能大模型为起点朝AGI走去。

在商汤这次推出的大模型体系中,备受关注的当是语言大模型「商量」,它的口号是「商量商量,都能解决」。
「商量」一名,实际上点出了ChatGPT类模型的核心,即用户在多轮对话中,通过Prompt「魔法」调教,挖掘大模型解决问题的能力。
在现场,徐立向我们演示了如何与「商量」商量商量。在逻辑推演、语言理解的广度和深度,以及知识的自动及时更新等方面,「商量」的表现都令人印象深刻。
你可以和「商量」互动创作一个故事,过程中用合适的Prompt能引导它讲故事的走向:


对于数学推理题,「商量」也能回答得有理有据:

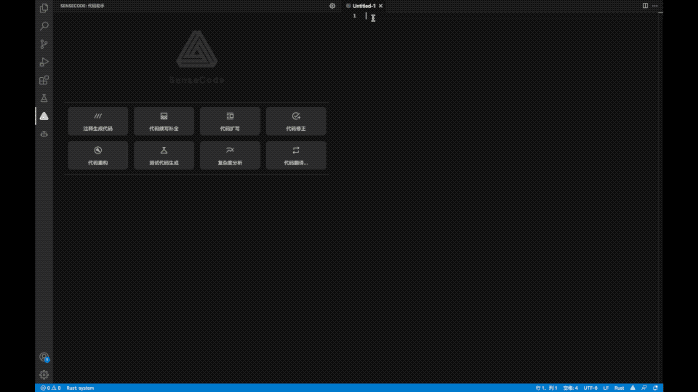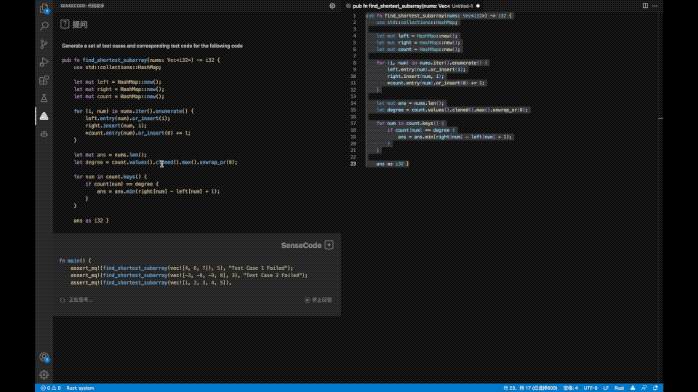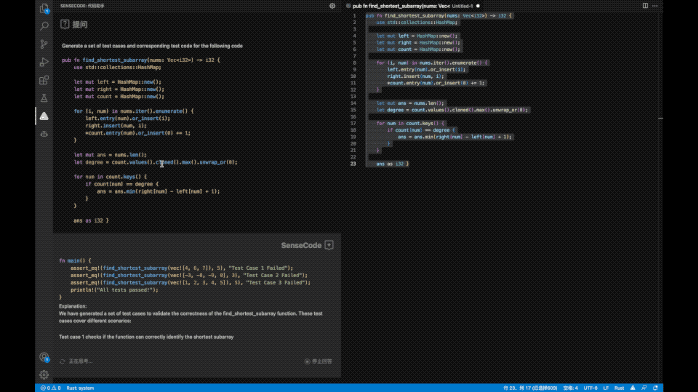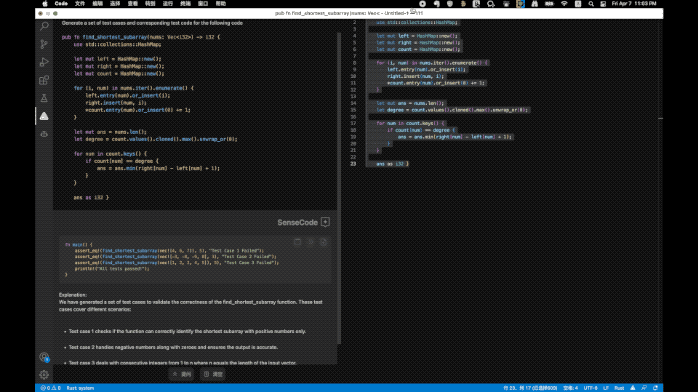
除了通用的对话能力,商汤还基于语言大模型打造了PDF文件阅读助手、AI代码助手、健康咨询助手等工具。
其中AI代码助手能提供代码补全、注释生成代码、测试代码生成、代码翻译、代码修正、代码重构、复杂度分析等功能。据内部测试,使用AI代码助手的编程效率可提高62%,未来程序员们可以减少枯燥的重复性工作、专注创造性编程了。
基于「日日新」大模型体系,商汤此次还发布了一系列的AIGC模型及应用,包括:
文生图创作平台「秒画 SenseMirage」、数字人视频生成平台「如影SenseAvatar」、3D内容生成平台「琼宇 SenseSpace」/「格物 SenseThings」等。 这些应用不仅名字取得典雅而不失贴切,而且其AI生成能力都十分惊艳。

使用「秒画」,基于单卡A100支持,2秒就能获得一张512K分辨率的图片,而且光影真实、细节丰富、风格多变:
一只戴着珍珠耳环的鹦鹉,维米尔风格,12K,高画质,高清,Octane Render


令人惊叹的史诗中国古代主题,飞龙,巨大,恐高症,青白色薄荷,山脉,云朵,全景,极端全景,中国墨水风格。艺术风格,动态,电影,令人惊叹,逼真的明暗处理,生动,充满活力,8k,辛烷值渲染,不真实,高度细致,概念艺术

更令人称奇的是,只需要20张训练图片,人人都能在5分钟内定制属于自己的LoRA模型。比如当你使用想生成「80年代港风」女子人像,但结果并不理想时,就可以上传20张风格更为贴近的图片,经过几步点击后得到新的LoRA模型。这时再输入相同的Prompt,生成的图像风格相似度就会显著提升。
 上行图片由自训练LoRA模型生成
上行图片由自训练LoRA模型生成在数字人视频生成平台上,只需要5分钟的真人视频,你就可以用「如影」制作自己的数字人分身,声音动作自然、口型准确,还能说多语语言。这在短视频、电商直播、教育等领域都大有用武之地。

借助「琼宇」和「格物」,用户则可以更高效、低成本地生成三维场景和精细化物件,元宇宙触手可及。
其中,「琼宇」专注于复刻和还原真实空间,其空间重建生成能力可达大城市级尺度,100平方公里的空间也不在话下。传统人工建模10000人/天的建模任务,通过琼宇只需要2天就能完成。

「格物」支持物体3D内容生成,使用它来复刻还原物体的光照、材质细节,效率相比传统建模能提升400%。

—— 02 ——
从视觉走向多模态
超大规模神经网络的能力「涌现」,是一种发现而非发明。ChatGPT演示了AI大模型的能力,建立了人们对大模型实现通用人工智能(AGI)潜力的共识,也掀起了AIGC淘金热。
对商汤而言,ChatGPT则印证了:过去几年,商汤做对了。
在国内群雄逐鹿AI大模型的当下,商汤在其中究竟扮演了怎样的角色?雷峰网(公众号:雷峰网)的观点是,各家有各家的位置。商汤的位置已经清晰:
一是「日日新SenseNova」大模型体系以CV、NLP、AIGC等为核心,目标打造多模态大模型、最终通向AGI;
二是拥有业内稀缺的大模型专业基础设施SenseCore AI大装置;
三是以「大模型+大装置」的路线在业务和行业落地。
自2018年起,商汤便在往通用模型的方向走,在2019年预见性地储备了1000张GPU。10亿参数的图像大模型就是2019年发布,在之后的招股书中,商汤更是把AI大模型的布局写了进去。到2022年,商汤训练出了320亿参数的通用视觉大模型,是迄今全球最大的通用视觉模型,在目标检测、图像分布、多物体识别等任务上取得了非常好的性能。
2021年,商汤也启动了语言大模型的训练,并在NLP顶级赛事中拿下过多个第一。最近则调动资源火速训练出了1800亿参数的中文语言大模型「商量SenseChat」,已经开始和客户对接测试。
多模态方面,商汤在今年三月开源了30亿参数的「书生2.5」大模型,具备很强的图文跨模态开放任务处理能力,而且是目前全球开源模型中ImageNet准确度最高、规模最大、物体检测标杆数据集COCO中唯一超过65.0 mAP的模型。
这种依托领先的视觉技术优势,逐步向多模态拓展的技术路线,既是视觉AI领跑者商汤的必然选择,也在技术层面有着逻辑合理性。
视觉是人类获取周遭世界信息的最主要渠道,五感中大约有80%的信息都是以肉眼获取的。另外,视觉信息也在互联网数据分布中占很高的比例,据统计,若爬取整个互联网的文本数据,经过数据清洗后得到的只有不到10个T,而已有的图像公开数据集中最大的包含50亿张图像,大小约240T,所谓「一图胜千言」,AI要处理的视觉信息远比文本信息要多得多。所以,在视觉与语言信息具有互通性的前提下,以视觉为起点去扩展大模型的其他能力如语言、代码、数学等,符合人类理解世界的方式。
还有很重要的一点是,以ChatGPT为代表的语言大模型其核心并不在于「语言」,而在于作为一种新方法的「大模型」。在这一波语言大模型浪潮中,为什么原本做NLP的一批公司并未如预想的那样崛起,反而有的还「倒」在了大模型的脚下?就是因为通用大模型基于深度学习和超大规模神经网络(Transformer为代表),把这些公司原本在传统NLP技术上的竞争优势给无情抹平了。
所以,基于对大模型、大装置领域的长期积累,以及基础设施投入,让商汤在短时间内交出了千亿级别的语言大模型,并确立了完整的商汤日日新大模型体系。
在商汤看来,多模态大模型是通往AGI的光明之路。如果以人的受教育程度来衡量大模型的智能水平,GPT-4目前已能媲美90%以上的大学生。让大模型能够「考上大学」、「通修全科」,这也是商汤的AGI愿景。
—— 03 ——
算力的长跑
大模型非一日之功,大算力更非一天能建成。大模型浪潮掀起,但入局者大多面临着算力之困:许多下场的企业并没有足够的算力储备;英伟达A100和A800仍是训练大模型的最优选,国产芯片目前还仅能去做小模型和中模型的训练和推理,在大模型上性价比没那么高。
真正能够马上提供足够算力支持的没有几家,商汤就是其中一个。支持商汤大模型训练的SenseCore AI大装置目前拥有2.7万块GPU,是亚洲最大的智算中心之一。其输出的算力十分惊人:
峰值算力高达5000Petaflops;可以并行训练20个以上的ChatGPT类模型;1750亿参数的GPT-3在AIDC一天就能完成1次训练。

商汤临港智算中心AIDC商汤之所以能在这一波迅速入局,一个重要原因是商汤很早意识到算力的重要性并有长期布局。
商汤科技CEO徐立提出,AGI时代的大模型新公式是:大模型参数量×处理的数据量=计算量。其中,大模型参数量的指数级增长对算力的需求无需多言,商汤对大算力的预见性还在于多模态数据方面,这种预见很自然地发生在商汤的视觉模型研发经验中。
一个对比是,由于视觉数据的数量、质量和信息容量上都比语言数据要大得多,视觉模型对算力的消耗相当于语言模型的10倍。商汤在2019年训练出的10亿参数视觉模型,实际上就要求有支撑100亿语言模型训练的算力,这促使商汤很早就开始了算力长跑。
不过,高算力并不是简单地堆砌大量GPU卡就能实现,而是需要一个有强大系统设计的超大规模训练集群,因为大模型的计算量是GPU数量、并行效率、运行时间三者的乘积。这当中,并行效率和运行时间是两个技术关键,商汤大装置在这两个方面已经造就了工程奇迹。
一是并行效率非常高。从1千卡级到3、4千卡级,再到1万张卡级大规模集群的部署,训练集群的规模会有可预见的增长,但大模型训练的并行效率才决定了实际算力。如果系统效率低下,1万张卡相比1千张卡的训练效率只能提高2倍,经济上很不划算。现在商汤大装置在千卡级已经达到90%以上的线性度,能够以最大4千卡的规模集群进行单任务训练。
事实上,商汤很早就奠定了强大的系统和架构能力。19年商汤曾创造一个记录,实现了全球最快的AlexNet训练速度,当时已具备并行计算上千块GPU的能力,这是很罕见的。
二是系统稳定性极强,目前可以做到7天以上不间断的稳定训练。商汤科技联合创始人、大装置事业群副总裁陈宇恒介绍,每天每1千张GPU中,约有1张卡会出现故障,那么有1万张卡的时候,每天的故障率会更多,估计下来,平均无故障时间可能就只有一两个小时,这样的系统是没法使用的。
商汤从硬件的可靠性到软件的容错度都实现了良好的设计,7天,实际上是非常了不起的,即使是背靠微软Azure的OpenAI也望尘莫及,据官方公布,OpenAI训练模型时两三天就可能断一次点。
—— 04 ——
「大模型+大装置」双轮落地
商汤一次性推出大模型体系和多个生成式AI应用,向业界表明,商汤大模型的技术与落地是在同时进行的。
从数十亿参数级的大模型开始,在每一次的迭代中,商汤都将大模型用在实际的产品和行业中,构建用户反馈的闭环。通过飞轮效应,一方面把模型越做越大,另一方面把模型越做越有用,而非一步登天地做出一个万亿级模型、却无法在真实场景中落地。
这种更为平滑的路线,适合商汤自身,也向行业释放了大模型的生产力。
如今,商汤的产品体系和技术体系,都可以依托大模型去做支撑。「日日新」大模型体系已经深度结合在商汤的智能汽车、智慧生活、智慧商业、智慧城市四大业务板块中。
比如在自动驾驶方面,商汤已通过视觉大模型解决了迈向L3、 L4商用级过程之中的至少两个痛点。一是把视觉大模型用作一个过滤器和半自动标注的机器人,去进行数据的筛选和预标注,能提高4倍的效率。二是视觉大模型能避免数据遗忘,有非常强的泛化能力,因此能解决传统小模型无能为力的Corner Case(边缘场景)问题。
另外在生物医药领域,商汤去年与生物企业合作,通过AI大装置为蛋白质结构大模型提供推理算力,把推理时间缩短了60倍,只需要数分钟就能得到蛋白质结构预测结果。

同时,商汤还通过大装置AI云将大模型的能力输出到了各个行业和场景中。
关于大模型的行业落地,最近很热的一个概念是「模型即服务」(Model as a Service,MaaS )。在商汤看来,MaaS只是AI大模型商业化、产品化的其中一个模式,人工智能即服务(AI as a service,AIaaS)是一个包含更广的概念。2022年,商汤AIDC开启商业化,将AI能力移植上云,在包括MaaS在内的各个层面都提供了不同服务和商业模式的方向:
•在计算基础设施服务层(IaaS),提供AI专用的算力存储网络服务,输出大算力。
•在平台层(PaaS):既提供多种MaaS服务,包括自动化数据标注平台「商汤明眸SenseAnnotation」、自定义大模型训练、模型增量训练、模型推理部署、开发效率提升等,同时也开放API接口,支持自由调用「日日新」大模型的各项AI技术能力。
这一套服务在商业化上是很成功的。数据显示,目前大装置已经服务8家客户训练大模型,总共提供了7000多张GPU卡,支持了超过10个大模型训练项目。在收入方面,大装置的对外服务收入占到了整个智慧商业板块收入的20%,AlaaS收入约2.93亿元。
如今的商汤已经进入无人之境。在算力基础设施层面,如何将上万块的计算卡与低延迟、高稳定、高吞吐的方式去互联,完成超大规模训练任务,是商汤接下来要应对的挑战。在大模型技术层面,未来怎样通过端云的配合完成大模型的应用闭环,也是一个长期命题。AGI的征途还很远,商汤会继续做时间的朋友。
(公众号:雷峰网)
雷峰网原创文章,未经授权禁止转载。详情见转载须知。

好了,关于类ChatGPT新玩家「商量」入场,商汤如何「日日新」?就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “考生”下半年自考即将开始 省考试院发出温馨提示
- “父亲”父亲的眼神杀
- “这是”自内耗到自洽
- “大桥”G3铜陵长江公铁大桥先导索过江
- “某甲”父亲被羁押继母要离婚,未成年女儿谁来抚养?法官多方努力,难题解决了!
- “亚马逊”哪些以色列芯片公司已被美国企业收购?
- “结构”结核杆菌致病机制获揭示
- “装修”装修公司老板明知公司亏损仍吸引客户签合同,骗取上百人700余万,被判11年
- “射电”穿越80亿光年的快速射电暴源于一场“星系交通事故”
- “必胜客”必胜客最黑暗的料理来了
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等
- “融资”国内AI大模型赛道火热,大厂积极跟投布局
- “模型”在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了
- “图像”OpenAI终于Open一回:DALL-E 3论文公布、上线ChatGPT,作者一半是华人









