“模型”在图像、视频生成上,语言模型首次击败扩散模型,tokenizer是关键
今天,很高兴为大家分享来自机器之心Pro的在图像、视频生成上,语言模型首次击败扩散模型,tokenizer是关键,如果您对在图像、视频生成上,语言模型首次击败扩散模型,tokenizer是关键感兴趣,请往下看。
机器之心报道
编辑:张倩、陈萍
为什么语言模型在视觉生成方面落后于扩散模型?来自谷歌、CMU 的研究表明,tokenizer 是关键。
大型语言模型(LLM 或 LM)一开始是用来生成语言的,但随着时间的推移,它们已经能够生成多种模态的内容,并在音频、语音、代码生成、医疗应用、机器人学等领域开始占据主导地位。
当然,LM 也能生成图像和视频。在此过程中,图像像素会被视觉 tokenizer 映射为一系列离散的 token。然后,这些 token 被送入 LM transformer,就像词汇一样被用于生成建模。尽管 LM 在视觉生成方面取得了显著进步,但 LM 的表现仍然不如扩散模型。例如,在图像生成的金标基准 —ImageNet 数据集上进行评估时,最佳语言模型的表现比扩散模型差了 48% 之多(以 256ˆ256 分辨率生成图像时,FID 为 3.41 对 1.79)。
为什么语言模型在视觉生成方面落后于扩散模型?来自谷歌、CMU 的研究者认为,主要原因是缺乏一个良好的视觉表示,类似于我们的自然语言系统,以有效地建模视觉世界。为了证实这一假设,他们进行了一项研究。

论文链接:https://arxiv.org/pdf/2310.05737.pdf
这项研究表明,在相同的训练数据、可比模型大小和训练预算条件下,利用良好的视觉 tokenizer,掩码语言模型在图像和视频基准的生成保真度和效率方面都超过了 SOTA 扩散模型。这是语言模型在标志性的 ImageNet 基准上击败扩散模型的首个证据。
需要强调的是,研究者的目的不是断言语言模型是否优于其他模型,而是促进 LLM 视觉 tokenization 方法的探索。LLM 与其他模型(如扩散模型)的根本区别在于,LLM 使用离散的潜在格式,即从可视化 tokenizer 获得的 token。这项研究表明,这些离散的视觉 token 的价值不应该被忽视,因为它们存在以下优势:
1、与 LLM 的兼容性。token 表示的主要优点是它与语言 token 共享相同的形式,从而可以直接利用社区多年来为开发 LLM 所做的优化,包括更快的训练和推理速度、模型基础设施的进步、扩展模型的方法以及 GPU/TPU 优化等创新。通过相同的 token 空间统一视觉和语言可以为真正的多模态 LLM 奠定基础,后者可以在我们的视觉环境中理解、生成和推理。
2、压缩表示。离散 token 可以为视频压缩提供一个新的视角。可视化 token 可以作为一种新的视频压缩格式,以减少数据在互联网传输过程中占用的磁盘存储和带宽。与压缩的 RGB 像素不同,这些 token 可以直接输入生成模型,绕过传统的解压缩和潜在编码步骤。这可以加快生成视频应用的处理速度,在边缘计算情况下尤其有益。
3、视觉理解优势。先前的研究表明,离散 token 在自监督表示学习中作为预训练目标是有价值的,如 BEiT 和 BEVT 中所讨论的那样。此外,研究发现,使用 token 作为模型输入提高了鲁棒性和泛化性。
在这篇论文中,研究者提出了一个名为 MAGVIT-v2 的视频 tokenizer,旨在将视频(和图像)映射为紧凑的离散 token。
该模型建立在 VQ-VAE 框架内的 SOTA 视频 tokenizer——MAGVIT 基础上。基于此,研究者提出了两种新技术:1)一种新颖的无查找(lookup-free)量化方法,使得大量词汇的学习成为可能,以提高语言模型的生成质量;2)通过广泛的实证分析,他们确定了对 MAGVIT 的修改方案,不仅提高了生成质量,而且还允许使用共享词汇表对图像和视频进行 token 化。
实验结果表明,新模型在三个关键领域优于先前表现最好的视频 tokenizer——MAGVIT。首先,新模型显著提高了 MAGVIT 的生成质量,在常见的图像和视频基准上刷新了 SOTA。其次,用户研究表明,其压缩质量超过了 MAGVIT 和当前的视频压缩标准 HEVC。此外,它与下一代视频编解码器 VVC 相当。最后,研究者表明,与 MAGVIT 相比,他们的新 token 在两个设置和三个数据集的视频理解任务中表现更强。
方法介绍
本文引入了一种新的视频 tokenizer,旨在将视觉场景中的时间 - 空间动态映射为适合语言模型的紧凑离散 token。此外,该方法建立在 MAGVIT 的基础上。
随后,该研究重点介绍了两种新颖的设计:无查找量化(Lookup-Free Quantization ,LFQ)和 tokenizer 模型的增强功能。
无查找量化
最近一段时间,VQ-VAE 模型取得巨大进展,但该方法存在一个缺点,即重建质量的改进与后续生成质量之间的关系不明确。很多人误以为改进重建就等于改进语言模型的生成,例如,扩大词汇量可以提高重建质量。然而,这种改进仅适用于词汇量较小时的生成,而词汇量非常大时会损害语言模型的性能。
本文将 VQ-VAE codebook 嵌入维度缩减到 0 ,即 Codebook  被替换为一个整数集,其中
被替换为一个整数集,其中 。
。
与 VQ-VAE 模型不同的是,这种新设计完全消除了对嵌入查找的需要,因此将其称为 LFQ。本文发现 LFQ 可以通过增加词汇量,提高语言模型的生成质量。如图 1 中的蓝色曲线所示,随着词汇量的增加,重建和生成都不断改进 —— 这是当前 VQ-VAE 方法中未观察到的特性。

到目前为止,可用的 LFQ 方法很多,但本文讨论了一种简单的变体。具体来说,LFQ 的潜在空间被分解为单维变量的笛卡尔积,即  。假定给定一个特征向量
。假定给定一个特征向量 ,量化表示 q (z) 的每个维度从以下获得:
,量化表示 q (z) 的每个维度从以下获得:

对于 LFQ ,q (z) 的 token 索引为:

除此以外,本文在训练过程中还增加了熵惩罚:

视觉 tokenizer 模型的改进
联合图像 - 视频 tokenization。为了构建联合图像 - 视频 tokenizer,需要一种新的设计。本文发现 3D CNN 的性能比空间 transformer 更好。
本文探索了两种可行的设计方案,如图 2b 将 C-ViViT 与 MAGVIT 进行结合;图 2c 使用时间因果 3D 卷积来代替常规 3D CNN。
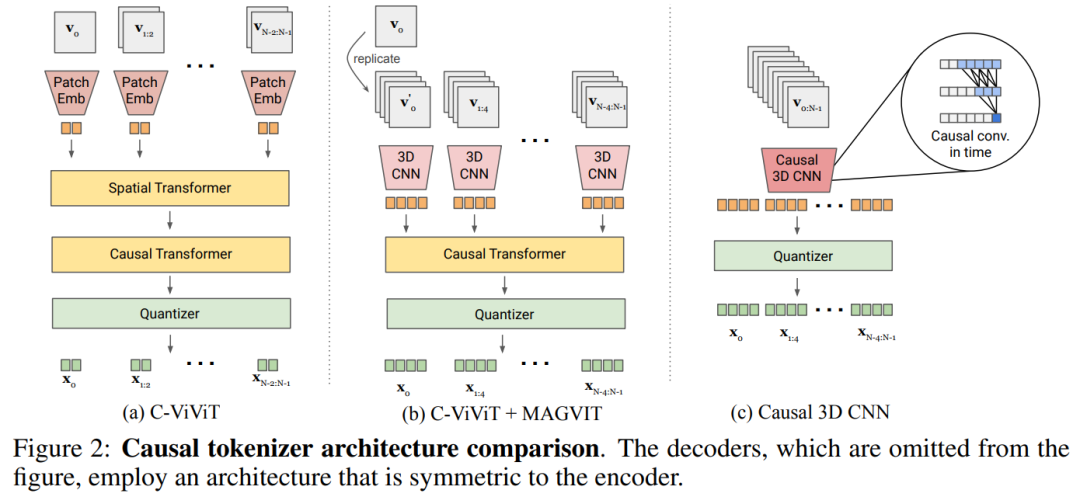 表 5a 对图 2 中的设计进行了经验比较,发现因果 3D CNN 表现最好。
表 5a 对图 2 中的设计进行了经验比较,发现因果 3D CNN 表现最好。
除了使用因果 3D CNN 层之外,本文还进行了其他架构的修改,以提高 MAGVIT 性能,比如本文将编码器下采样器从平均池化更改为跨步卷积;又比如在解码器中每个分辨率的残差块之前添加一个自适应组归一化层等。
实验结果
实验从三个部分验证了本文提出的 tokenizer 的性能:视频和图像生成、视频压缩,动作识别。图 3 直观地比较了 tokenizer 与先前研究的结果对比。

视频生成。表 1 显示了本文模型在两个基准测试中都超越了所有现有技术,证明了良好的视觉 tokenizer 在使 LM 生成高质量视频方面发挥着重要作用。
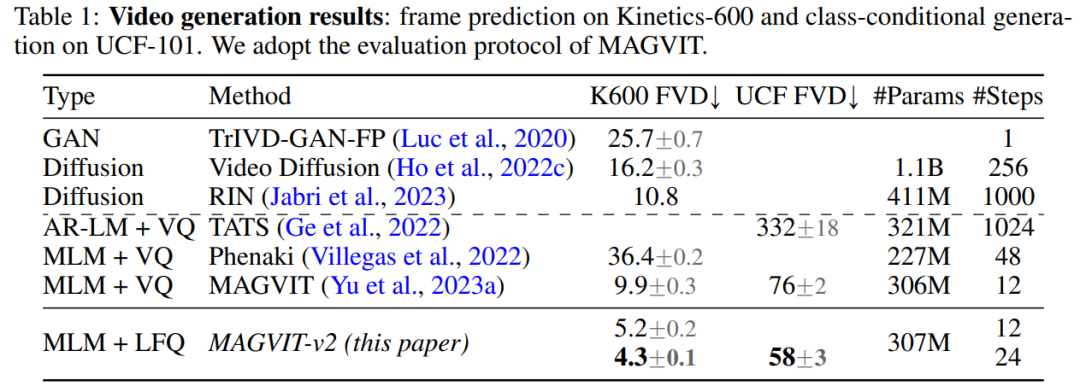 图 4 显示了模型的定性样本。
图 4 显示了模型的定性样本。
图像生成。本文在标准 ImageNet 类条件设置下对 MAGVIT-v2 的图像生成结果进行了评估。结果表明本文模型在采样质量(ID 和 IS)和推理时间效率(采样步骤)方面都超过了表现最好的扩散模型。
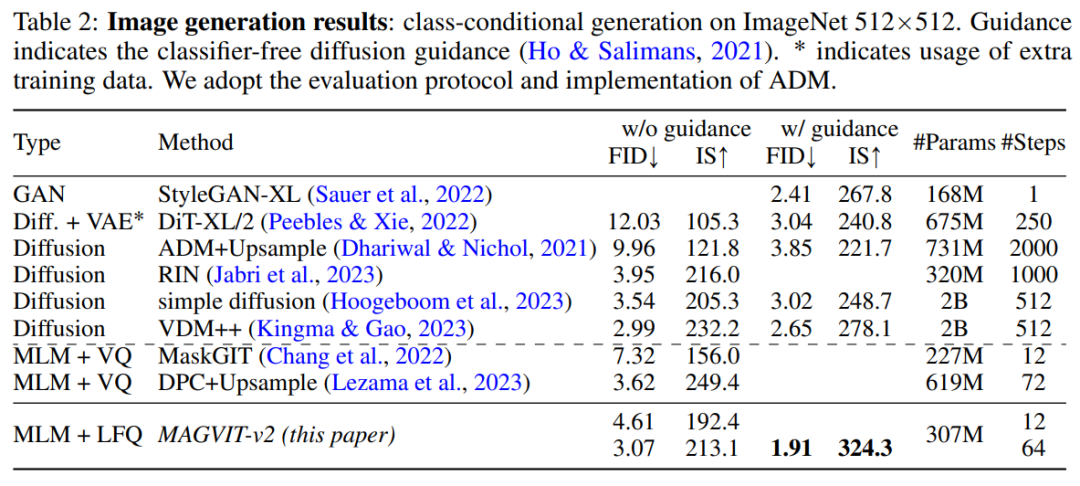 图 5 为可视化结果。
图 5 为可视化结果。
视频压缩。结果如表 3 所示,本文模型在所有指标上都优于 MAGVIT,并且在 LPIPS 上优于所有方法。

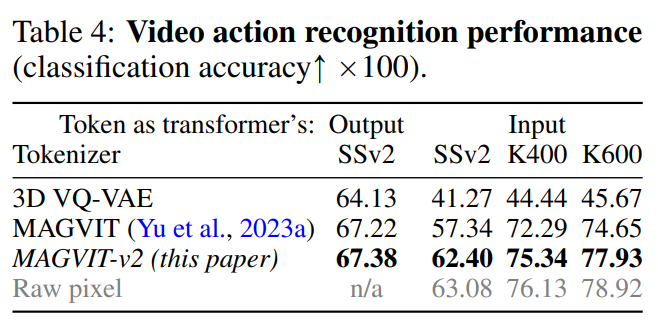
视频理解。如表 4 所示,MAGVIT-v2 在这些评估中优于之前最好的 MAGVIT。
好了,关于在图像、视频生成上,语言模型首次击败扩散模型,tokenizer是关键就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “小行星”我国2030年前后 实现载人登月
- “都是”A股的觉醒之年!
- “孩子”一生的功课
- “益康”倍益康上市几个月收入净利都大减 市值仅几亿 创始人张文有啥办法?
- “科幻”嘉宾共话科幻的未来:被视为“珍贵市场”,中国科幻正青春
- “灯会”红星观察|自贡灯会走出“春节舒适区”:首次试水中秋国庆主题灯会火出圈背后
- “华为”新麒麟全面替代!曝华为正在清理骁龙机型库存:掀起全线新品的“洪流”
- “鸟类”评论丨大楼玻璃贴膜防鸟撞,城市的天空如何助鸟自由飞翔?
- “同济大学”四川“无臂青年”彭超参与杭州亚残运会火炬传递,曾用脚写字考上同济大学研究生
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “视频”一个山东男人在中年离开编制后
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等
- “融资”国内AI大模型赛道火热,大厂积极跟投布局
- “模型”在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了









