“建模”遍览数年历史视频、挖掘用户隐藏兴趣,快手终身行为建模方案TWIN入选KDD 2023
今天,很高兴为大家分享来自机器之心Pro的遍览数年历史视频、挖掘用户隐藏兴趣,快手终身行为建模方案TWIN入选KDD 2023,如果您对遍览数年历史视频、挖掘用户隐藏兴趣,快手终身行为建模方案TWIN入选KDD 2023感兴趣,请往下看。
本期为大家介绍快手 - 社区科学线自研论文:TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou 本文发表于 2023 年 KDD Applied Data Science Track(录取率 25.4%),旨在解决传统的超长行为建模中长久存在的「两阶段中相似度度量标准不一致」问题,从而提升超长行为建模的精准度。

作者:常健新、张晨斌、傅智毅、臧晓雪、关琳、吕静、惠轶群、冷德维、牛亚男、宋洋
论文地址:https://arxiv.org/abs/2302.02352
1. 背景与 Motivation
快手,作为中国国民级短视频 APP,一直把痴迷客户作为算法设计的准绳和方向。每天,我们的推荐系统个性化地为每一个用户提供她最喜欢的视频内容,并为每一位创作者找到最知音的受众。为了达成高度个性化推荐这一目标,推荐系统需要充分利用一切宝贵的用户侧特征。
在这一背景下,终身行为建模(也叫做超长行为序列建模,Lifelong user behavior modeling),应运而生。顾名思义,终身行为建模就是从用户数月至数年中积累的几万个历史观看视频中,利用深度学习模块,准确地提取出用户隐藏的兴趣,从而助力推荐系统中的高阶任务,如 CTR 预估等。
1.1 行为序列建模方法
在早期研究中,短期行为建模算法(如 DIN,DIEN 等)往往采用各种 attention 机制,对短期历史行为做加权平均。其中,与 target video 更相似的行为被赋予高权重,而与 target video 不相似的行为则在加权中被压缩。

例如图一中,target video 是双板滑雪教学视频, 与滑雪户外相关的历史行为获得了更高的权重,而音乐唱片等不太相关的历史行为则获得了很低的权重。

然而,鉴于 Attention 机制中昂贵的计算,这些短期行为建模算法,往往只能处理 100 + 的行为序列。相反地,绝大多数快手的活跃用户,每天就会观看 100 多个视频,几个月下来,就能积累 1 万到 10 万个历史行为。所以,这些有效的短期行为建模算法无法直接被扩展到超长行为序列建模中。近年来,超长行为建模往往采取两阶段建模的方法。我们以这一领域的 SOTA,SIM 算法为例,为大家简要介绍两阶段终身学习算法的共同框架。
1.2 超长行为序列建模的 SOTA
两阶段超长行为建模的范式是:先用一个简单高速的 GSU 模块选择出与 target video 最相关的 top100 个行为,再用复杂精准的 ESU 模块,对这 100 个优胜者,做 target attention(TA),从而提取出超长序列中隐含的用户兴趣表征。如图二所示。

图二:两阶段建模的一般范式,其中 target video 是滑雪教学视频,GSU 粗筛出了滑雪、户外运动相关的视频供 ESU 做 TA
近年来,大量的两阶段建模方法层出不穷,它们的主要区别在于 GSU 依据什么标准来粗筛与 target video 相似的行为。例如,SIM Hard 的 GSU 简单地从历史行为中过滤出与 target video 相同的类别的行为,而 SIM Soft 通过某些预训练任务获得 embedding,计算 target 和历史行为的内积作为相似度量,而后筛选相似度最高的行为。ETA 使用局部敏感哈希 (LSH) 和汉明距离来近似计算相关性分数。SDIM 通过多轮哈希碰撞等方法对与目标行为具有相同哈希签名的行为进行采样。
1.3 两阶段建模方法的缺陷
尽管经过了广泛的研究,现有的两阶段终身行为建模算法仍然存在一个关键的缺陷:GSU 和 ESU 之间,相似度度量标准的不一致。例如:SIM 的 GSU 通过品类过滤或预训练任务中 embedding 的内积距离计算出来的距离度量,和 ESU 中基于 end2end 训练的 target attention,差距较大。如此,GSU 可能会筛选出 ESU 不认可的行为,浪费了 ESU 宝贵的计算能力,却只能在一些与 target 不太相关的行为中权衡注意力的分布。这种不一致性,极大地拉低了超长序列建模模块的表现力,从而伤害了 CTR 预估的精准度。
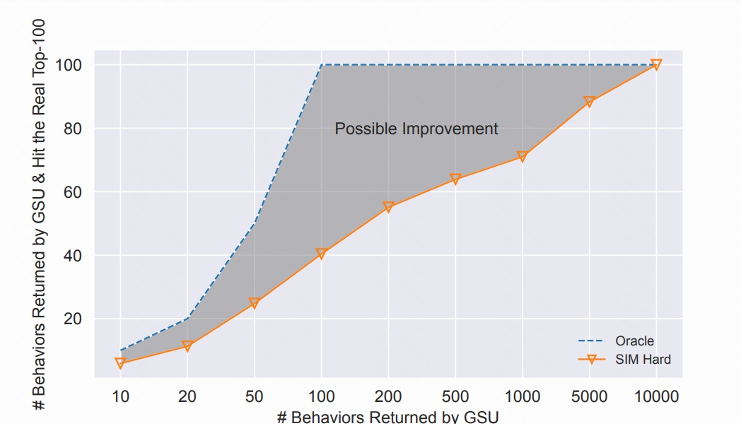
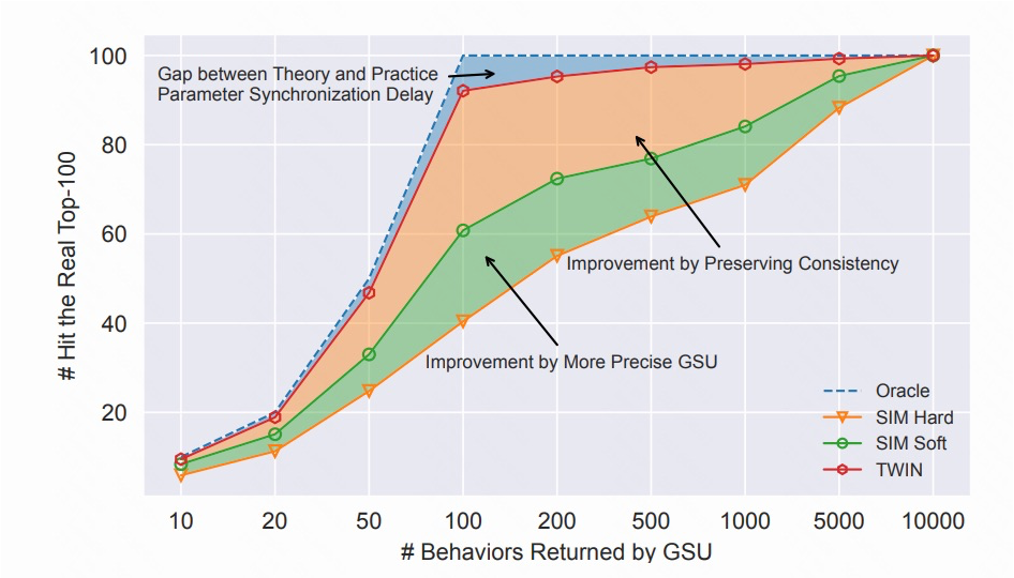
例如,我们在图三中,用具体的数字直观地说明一下这种不一致的严重程度。在一些小规模数据集上,我们可以不计成本做一个 Oracle,即用 ESU 直接从 1 万个历史行为中,找到 ESU 真正的 top100 作为 ground truth,对比用 SIM-hard 的 GSU 筛选出来的 topK。图中 x 轴代表 GSU 返回 K 个行为,y 轴代表 SIM hard 的 GSU 命中的 ground truth 个数。
我们可以看到,SIM 的 GSU 返回的前 100 个可能只有 40 个是真正的前 100,而 SIM 返回的前 200 也只有 57 个是真正的前 100。图中的灰色区域,就是留给我们解决两阶段不一致问题的提升空间。
所以,如何才能升级 GSU 的计算方法,使它能用与 ESU 一致的距离度量,从而找到在 ESU 中 Attention 权重较高的行为,是弥补现有两阶段算法的缺陷的关键点。
2. TWIN 算法
我们把本文提出的算法命名为 TWIN,即强调我们的 GSU 和 ESU,如同双胞胎一样,应用了同样的目标与行为之间的距离度量。如图四所示。
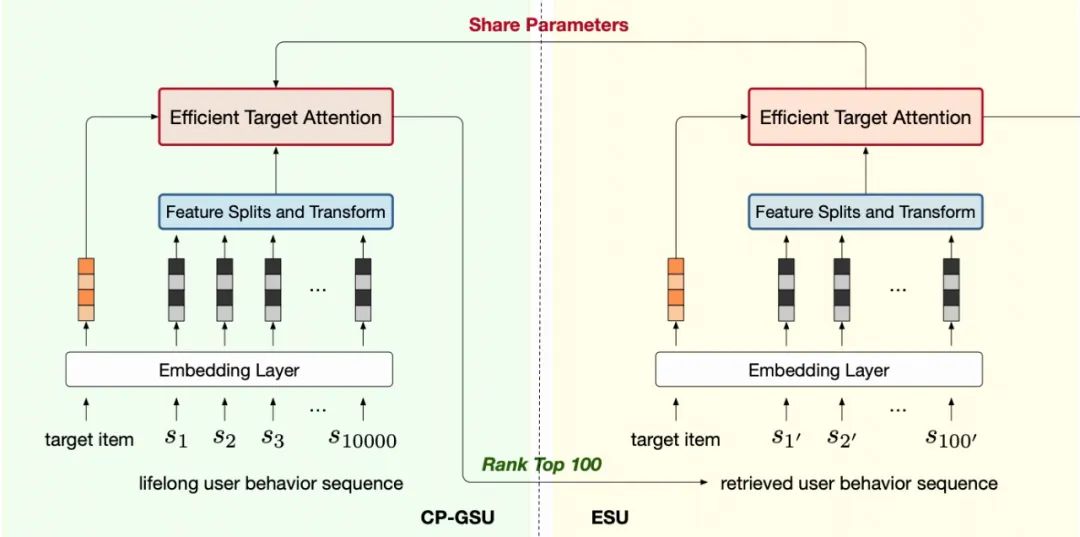
然而这种一致性的达成,是不平凡的。ESU 的距离度量依赖多头目标注意力网络(MHTA),计算极为耗时,所以一般只用在 100 个行为上。换句话说,我们需要解决的是,如何把通常应用于 100 个行为上的 MHTA 提升性能,从而扩展到 GSU 需要处理的 1 万到 10 万个行为上?
2.1 特征拆分与线性映射
在实践中,我们发现 MHTA 模块的计算瓶颈在于行为序列的线性映射,这也是把 MHTA 应用于超长序列的最需要加速的模块。本文中,我们巧妙地把行为序列的 embedding 拆分为两部分:

(表示序列长度,
表示 embedding 维度)
行为的固有属性
(inherent features),即该视频的与 user 行为无关的自有属性,例如视频的作者、时长、分类、video id 等。
行为的用户交叉属性
(user-item cross features),即特定 user 与 item 交互而产生的属性,例如用户的观看时长,用户的点赞反馈,观看时间戳等。
其中,固有特征,是跨用户行为系列共享的。即同一个 video id 对应下,即使在不同的用户序列里,
可以转换为高效的,查表 - 整合步骤。
相应行也是完全相等的。所以,加上必要的预计算 - 缓存策略,固有特征的线性映射
对于交叉特征,因为跨用户行为序列不共享,且每个用户与每个视频最多只交互一次,以上策略行不通,所以我们采用维度压缩的方式减少计算量。

即对个交叉特征的每一个,我们都把 embedding 通过线性变换压缩到维度为 1. 如图五所示。
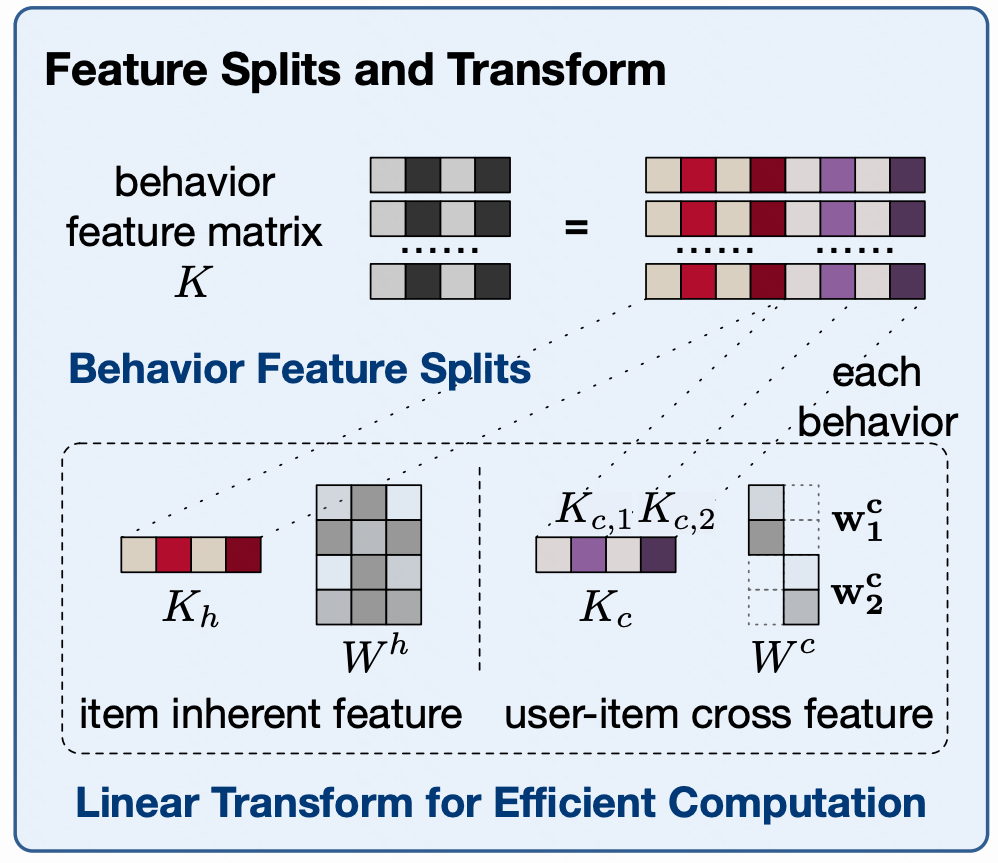 图五:特征拆分与线性映射
图五:特征拆分与线性映射2.2 TWIN 中的注意力机制
基于以上的线性变换,受传统 MHTA 方式的启发,我们建立了 TWIN 中的注意力机制。每个行为的权重是:

注意:
在 GSU 模块
涉及到 1 万到 10 万个行为序列的线性变换,虽然计算量大,但是却可以通过预计算 - 查表的方式加速。
是一个可学习的权重,表示各个 bias 项的相对重要性。
经过维度压缩后,计算量较小,可以实时计算。由于 query 中没有交叉属性,所以此项以 bias 项形式添加进来,
是 query 的线性变换,即 target video 的 embedding,计算量极小,与序列长度无关。
如此,GSU 中,以上权重虽然长度正比于序列长度(1 万到 10 万),却可以高效计算出。在得到 top100 权重后,我们筛选出了相应的行为,提供给 ESU 做 TA。
在 ESU 中,为了保证计算的精准度,且 。并计算 V 的加权均值:
。并计算 V 的加权均值:
项只剩下 100 维度,所以我们采用实时计算的方式获取

幸运的是,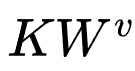
仍然只有 100 个行为,可以实时地计算。
在实际落地中,我们采用 MHTA 结构,用 4heads 来多角度学习用户的隐藏兴趣。
2.3 系统设计
图六详细地列出了系统设计图,整体分为 3 部分:
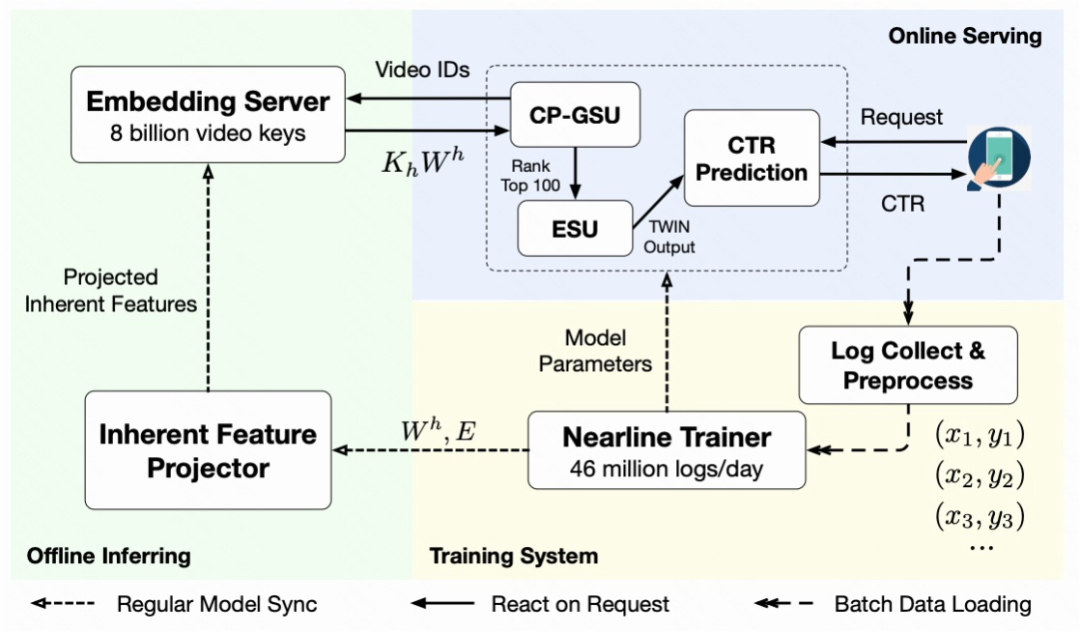
训练系统:每天实时训练 46billion 条用户 - 视频交互 log,并每 5 分钟一次,把用最新数据训练的最新模型参数和 embedding 同步给其他模块。以保证所有模块,都能得到最新的训练数据中的知识。
离线预计算:提前计算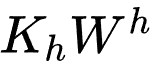
,并存储成字典格式,供在线 GSU 服务时查询。经过一定的长尾过滤,我们成功的把 video id 限制在 8billion 级别,并覆盖 97% 的线上请求。如此线性映射计算模块,可以用最新的 embedding 和线性映射权重矩阵,在 15 分钟内对字典全面滚动更新一次。
在线服务:我们的预计算 - 查询策略,节约了计算瓶颈(即
)中 99.3% 的计算量。现在该服务在峰时能每秒处理 3 千万视频的请求量。
3. 实验结果
在于 SOTA 两阶段算法对比中,我们验证了算法的有效性:
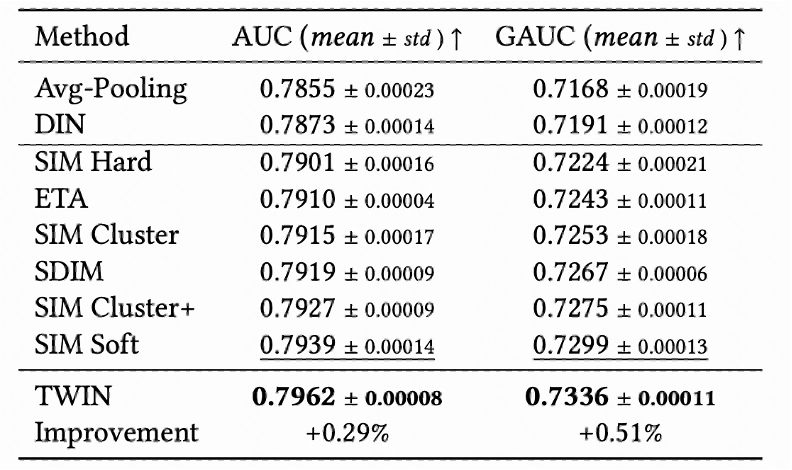
通过分析对 top100 的命中率,我们验证了两阶段的一致性。注意理论上我们的算法 GSU 和 ESU 完全一致,效果应接近 Oracle;然而,由于缓存延迟的 15 分钟,使得实际效果有一定不足(蓝色阴影区域):
我们设计丰富的消融实验,证明了不仅两阶段的结构一致很重要,GSU 和 ESU 之间的 embedding 同步也同样对我们的效果提升起到贡献。交叉特征计算的 Bias 项,虽然简单却对效果至关重要。同时,我们的预计算模块,虽然大幅节省了计算时间,对效果的负向影响却很微弱。

我们在三个业务模块中,通过线上 AB 对比实验,验证了算法的有效性。

撰文:吕静,快手模型与应用部
好了,关于遍览数年历史视频、挖掘用户隐藏兴趣,快手终身行为建模方案TWIN入选KDD 2023就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “小行星”我国2030年前后 实现载人登月
- “都是”A股的觉醒之年!
- “孩子”一生的功课
- “益康”倍益康上市几个月收入净利都大减 市值仅几亿 创始人张文有啥办法?
- “科幻”嘉宾共话科幻的未来:被视为“珍贵市场”,中国科幻正青春
- “灯会”红星观察|自贡灯会走出“春节舒适区”:首次试水中秋国庆主题灯会火出圈背后
- “华为”新麒麟全面替代!曝华为正在清理骁龙机型库存:掀起全线新品的“洪流”
- “鸟类”评论丨大楼玻璃贴膜防鸟撞,城市的天空如何助鸟自由飞翔?
- “同济大学”四川“无臂青年”彭超参与杭州亚残运会火炬传递,曾用脚写字考上同济大学研究生
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了
- “注意力”别再「浪费」GPU了,FlashAttention重磅升级,实现长文本推理速度8倍提升
- “侧翼”将专家知识与深度学习结合,清华团队开发DeepSEED进行高效启动子设计
- “蛋白质”利用进化扩散进行蛋白生成,微软开源新型蛋白质生成AI框架EvoDiff
- “字符串”重温图灵原理,感受反证法的力量
- “缺陷”中国移动上研院的“唐山海泰5G+工业视觉质检项目”
- “缓存”6.7k Star量的vLLM出论文了,让每个人都能轻松快速低成本地部署LLM服务
- “大赛”决战来袭!第二届琶洲算法大赛决赛即将举办
- “手柄”光学追踪+裸手识别,是时候跟游戏手柄说再见了吗?
- “量子”共探量子计算未来,中国移动第四届科技周“量子计算算法与应用”分论坛召开









