“模型”科学家用大语言模型增强视觉-语言理解,验证GPT-4多模态生成能力的背后原因
今天,很高兴为大家分享来自DeepTech深科技的科学家用大语言模型增强视觉-语言理解,验证GPT-4多模态生成能力的背后原因,如果您对科学家用大语言模型增强视觉-语言理解,验证GPT-4多模态生成能力的背后原因感兴趣,请往下看。
来源:DeepTech深科技
三月中旬,OpenAI 正式发布了 GPT-4,并向我们展示了其所具备的非凡的多模态能力:基于手写文本指令构建网站、生成详细准确的图像描述、解释丰富有趣的视觉现象……不过,需要说明的是,OpenAI 并未公开任何与 GPT-4 有关的技术细节。
来自沙特阿卜杜拉国王科技大学的研究团队认为,GPT-4 拥有卓越的多模态生成能力的主要原因在于,其使用了更为先进的大型语言模型。并且,为了验证他们提出的这个假设,其还构建了一个新模型,并将其命名为“MiniGPT-4”。
2023 年 4 月 20 日,相关论文以《MiniGPT-4:使用高级大型语言模型增强视觉-语言理解》(MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models)为题在预印本网站 arXiv 上发表[1]。
 图丨相关论文(来源:arXiv)
图丨相关论文(来源:arXiv)阿卜杜拉国王科技大学博士研究生朱德尧和陈军为该论文的共同第一作者,阿卜杜拉国王科技大学助理教授穆罕默德·埃尔霍西尼(Mohamed Elhoseiny)担任论文的通讯作者。
 图|左起(1)
图|左起(1)据介绍,该模型被建立在开源模型 LLaMA 的基础之上,将大型语言模型 Vicuna 作为语言解码器。在视觉感知上,其使用了来自于视觉语言模型 BLIP-2 的预训练视觉组件。此组件由 ViT-G/14 和 Q-Former 组成。
同时,该团队用一个投影层,将视觉模型和语言模型进行了对齐,使 MiniGPT-4 能够实现许多与 GPT-4 类似的功能,比如,生成复杂的图像描述、创建网站等等。
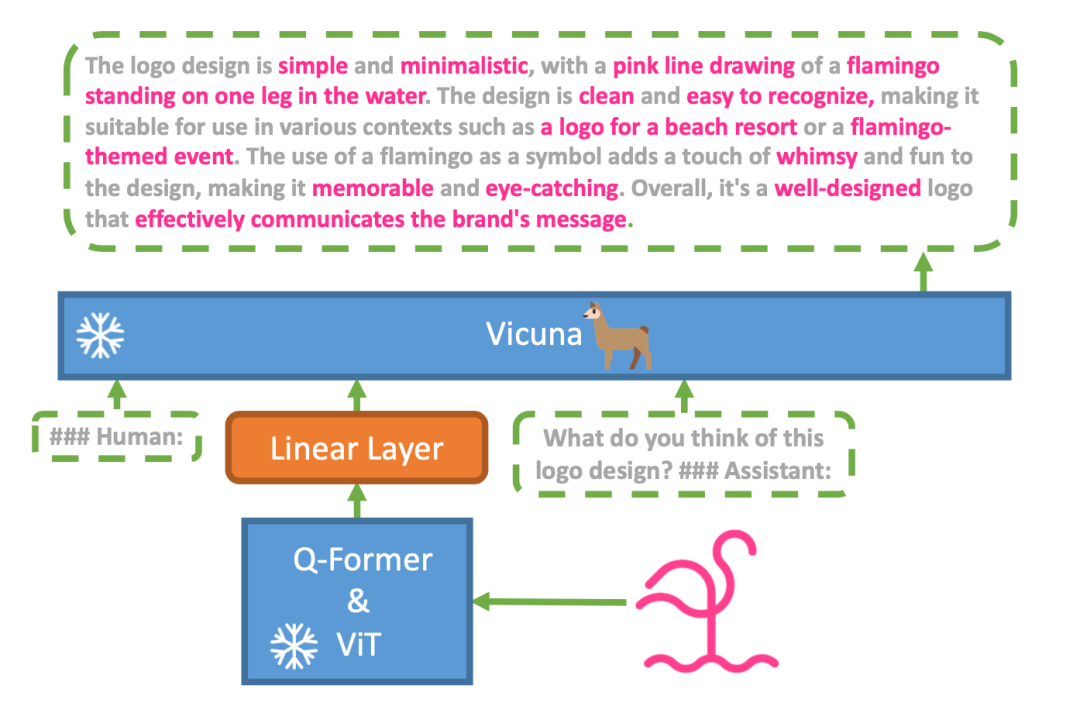 图丨MiniGPT-4 的架构(来源:arXiv)
图丨MiniGPT-4 的架构(来源:arXiv)他们起初在 4 个 A100 GPU 上,对该模型进行了第一阶段的传统训练,后来发现简单地对齐视觉模型和语言模型,并不能训练出像聊天机器人这样的、具有视觉对话能力的高性能模型。
与此同时,他们也发现,在对原始的图像-文本进行预训练的过程中,模型所生成的语言输出会缺乏连贯性。为了解决该问题,他们在第二阶段的训练中,构建了一个小型数据库,用 3500 个高质量的、对齐良好的图像-文本对,来提高模型的稳定性和生成语言的可用性。
“在第二阶段,我们只用了 3500 个数据,也只训练了七分钟,效果就有了大幅度提升,这是让我和团队感到很惊喜的一点。”朱德尧表示。
不仅如此,他们还在 MiniGPT-4 中,做了一些 GPT-4 演示中并未展示出的其他有趣能力。例如,MiniGPT-4 可以通过观察植物生病的照片,判断植物的病情并提出解决方案;可以通过观察食物照片,直接生成详细的食谱;可以受图像的启发为产品写广告等等。
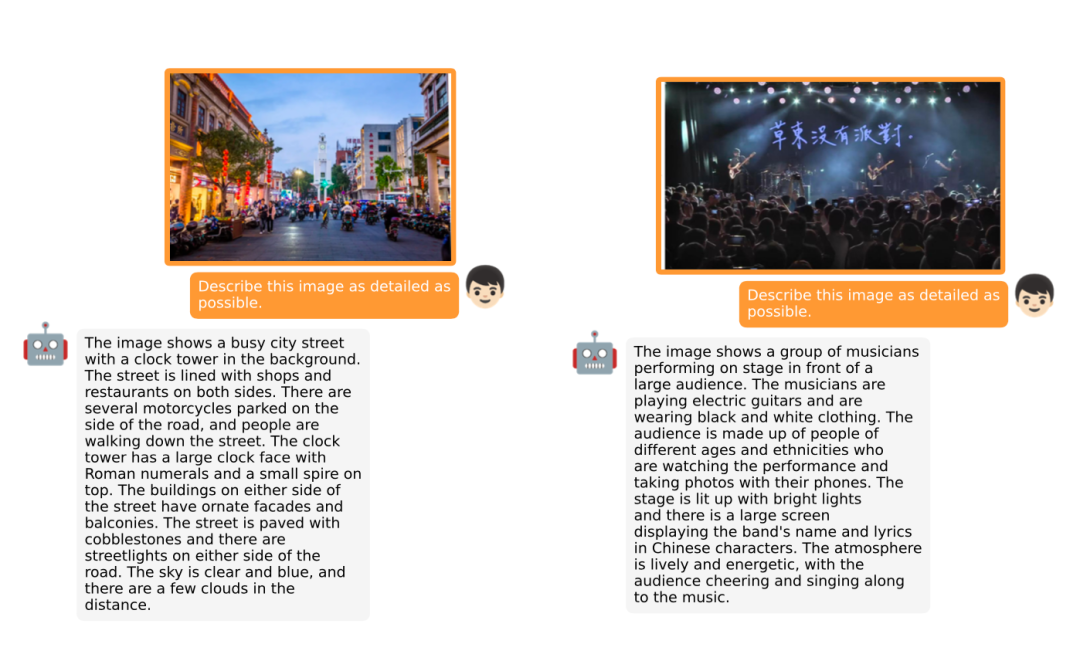 图丨详细图像描述(来源:arXiv)
图丨详细图像描述(来源:arXiv)总地来说,该研究证明了 MiniGPT-4 通过使用预训练的视觉编码器和大型语言模型,得到了很高的计算效率。并且,其能够处理像 GPT-4 演示中所展示出的那些能力。
“现在只要给我们一个比较先进的纯文本式的大型语言模型,就能在 10 小时之内让其‘看见’图片。”朱德尧说。
作为该论文的主要作者,朱德尧和陈军过往的求学经历有些不同。前者本科时所学的专业是机械电子工程,硕士转为电子信息工程,博士阶段才来到阿卜杜拉国王科技大学攻读计算机科学。而后者自本科开始就专注于计算机科学专业,已经在多模态、语言生成模型等方向有了一定积累。
两人相识于阿卜杜拉国王科技大学,均属于埃尔霍西尼助理教授课题组的一员。
谈到为何选择开展这项研究,朱德尧表示:“此前我们曾对多模态相关的大模型做过深入研究,比较了解传统多模态大模型的能力边界。当 OpenAI 公布 GPT-4 的演示时,我们完全被震撼到了,没想到现在已经能做到这个地步,同时又很好奇他们到底是怎么做出来的。”
与此同时,他们又希望在以往研究的基础之上继续向前,让多模态大模型的能力实现进一步突破。上述原因是他们开启这项研究的主要动力。
据了解,该论文在发表后赢得了大量的关注和传播,并收到许多来自行业内外的合作邀约。他们的项目在 GitHub 上 三天内迅速斩获 10000 星。
同时,朱德尧和陈军也将在今年年底迎来博士毕业,因此接下来他们计划基于自己的研究成果,围绕创业、找工作等方向做出选择。
对于是否选择创业,陈军也有自己的看法。 “虽然现在这个领域发展得很快,但还是有很多基础的问题没有解决。我们接下来会在技术上继续耕耘,以后可能会选择一个合适的时机再进行创业。” 他这样说。
参考资料:
1.D., Zhu, J., Chen, X., Shen. et al. MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models. arXiv:2304.10592.https://doi.org/10.48550/arXiv.2304.10592
好了,关于科学家用大语言模型增强视觉-语言理解,验证GPT-4多模态生成能力的背后原因就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “在我”忆来只把旧书读
- “科博会”芜湖科博会集中展示大国重器
- “诗人”带着大海散步的人
- “宁德”宁德时代三季报:业绩增速放缓、海外市场份额扩大
- “新材料”信金控股完成新一期人民币基金首关
- “同比增长”失守3000点后,A股市场的危与机|智氪
- “商务部”商务部:达成共识!
- “基金”又一家基金公司换董事长,年内公募高管变动人数增至321人
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “教师”北京化工大学回应学院院长被指骚扰教师:已成立工作专班,对师德失范问题零容忍
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等
- “融资”国内AI大模型赛道火热,大厂积极跟投布局
- “模型”在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了
- “图像”OpenAI终于Open一回:DALL-E 3论文公布、上线ChatGPT,作者一半是华人









